 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Conditioned Dialogue Generation Based on Pre-trained Language Model
Paper and Code
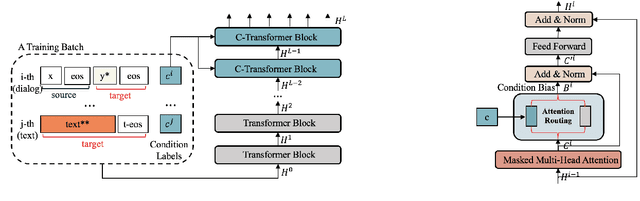
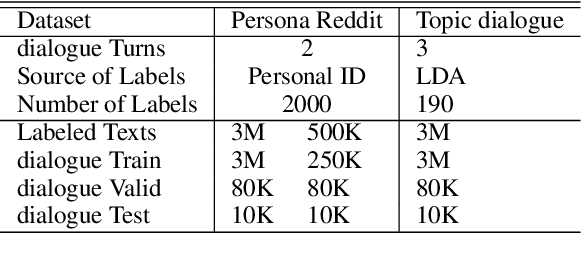
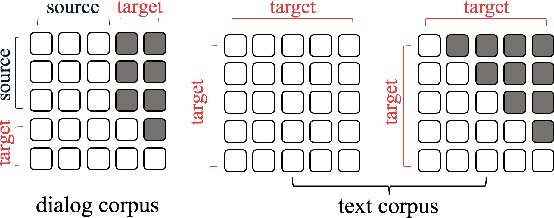
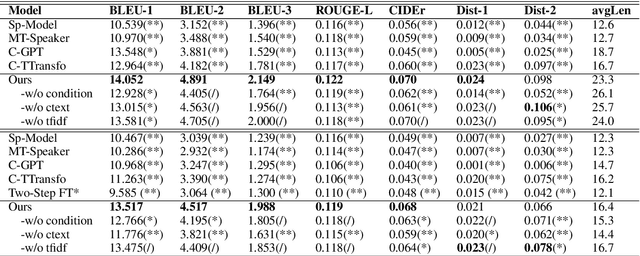
We investigate the general problem of conditioned dialogue, in which a condition label is used as input to designate the type of the target response such as a persona. A major challenge for conditioned dialogue generation is the lack of substantial dialogue data labeled with conditions. Thus, we propose to complement the labeled dialogue data with labeled non-dialogue text data, and fine-tune BERT based on them. Our fine-tuning approach utilizes BERT for both encoder and decoder via different input representations and self-attention masks in order to distinguish the source and target side. On the target (generation) side, we use a new attention routing mechanism to choose between generating a generic word or condition-related word at each position. Our model is instantiated to persona- and topic-related dialogue. Experimental results in both cases show that our approach can produce significantly better responses than the state-of-the-art baselines.