 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT for Joint Multichannel Speech Dereverberation with Spatial-aware Tasks
Paper and Code
Oct 22, 2020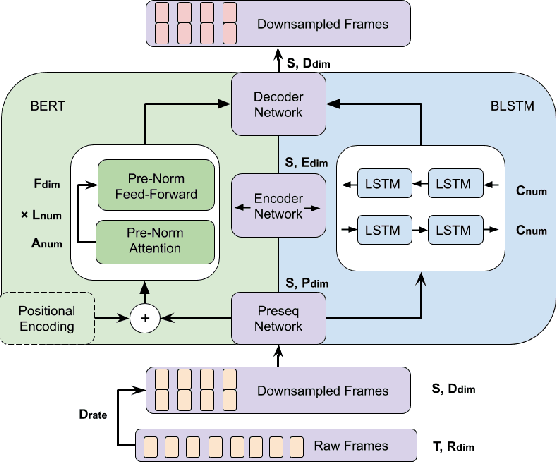


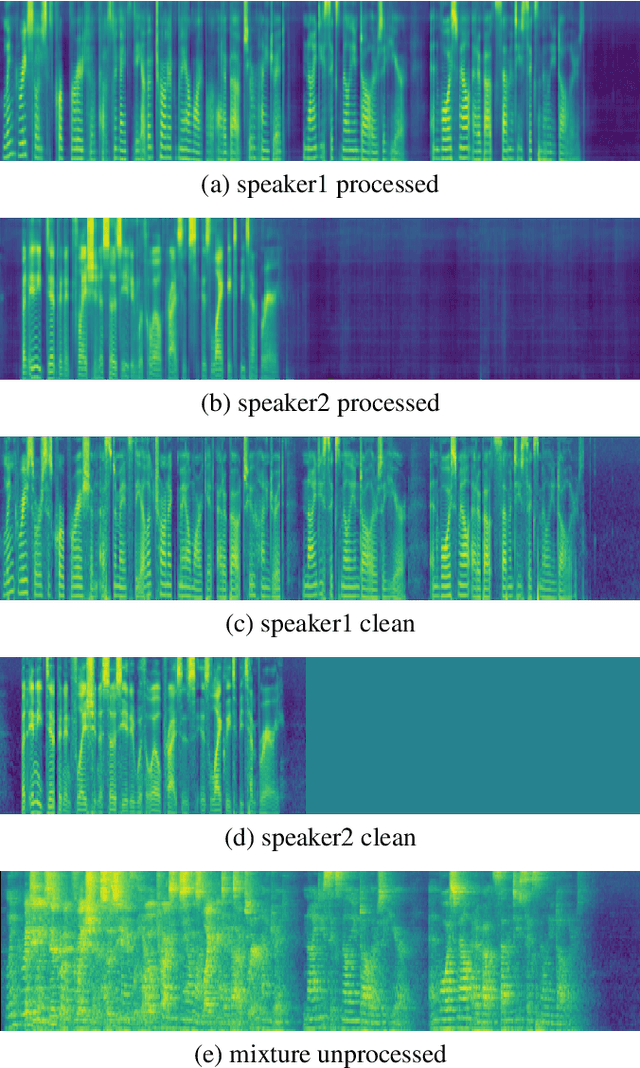
We propose a method for joint multichannel speech dereverberation with two spatial-aware tasks: direction-of-arrival (DOA) estimation and speech separation. The proposed method addresses involved tasks as a sequence to sequence mapping problem, which is general enough for a variety of front-end speech enhancement tasks. The proposed method is inspired by the excellent sequence modeling capability of bidirectional encoder representation from transformers (BERT). Instead of utilizing explicit representations from pretraining in a self-supervised manner, we utilizes transformer encoded hidden representations in a supervised manner. Both multichannel spectral magnitude and spectral phase information of varying length utterances are encoded. Experimental result demonstrates the effectiveness of the proposed method.