 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Traffic Fingerprinting: Large-scale Inference under Realistic Assumptions
Paper and Code
Oct 19, 2020
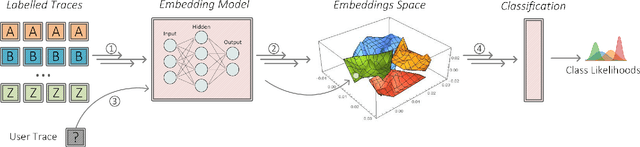
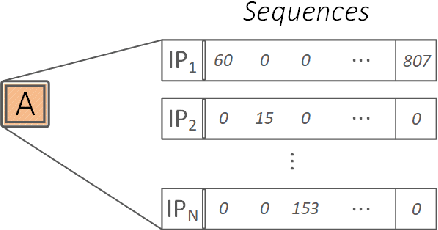
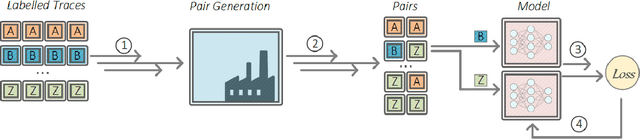
The widespread adoption of encrypted communications (e.g., the TLS protocol, the Tor anonymity network) fixed several critical security flaws and shielded the end-users from adversaries intercepting their transmitted data. While these protocols are very effective in protecting the confidentiality of the users' data (e.g., credit card numbers), it has been shown that they are prone (to different degrees) to adversaries aiming to breach the users' privacy. Traffic fingerprinting attacks allow an adversary to infer the webpage or the website loaded by a user based only on patterns in the user's encrypted traffic. In fact, many recent works managed to achieve a very high classification accuracy under optimal conditions for the adversary. This paper revisits the optimality assumptions made by those works and discusses various additional parameters that should be considered when evaluating a fingerprinting model. We propose three realistic scenarios simulating non-optimal fingerprinting conditions where various factors could affect the adversary's performance or operation. We then introduce a novel adaptive fingerprinting adversary and experimentally evaluate its accuracy and operation. Our experiments show that adaptive adversaries can reliably uncover the webpage visited by a user among several thousand potential pages, even under considerable distributional shift (e.g., the webpage contents change significantly over time). Such adversaries could infer the products a user browses on shopping websites or log the browsing habits of state dissidents on online forums and encyclopedias. Our technique achieves ~90% accuracy in a top-15 setting where the model distinguishes the article visited out of 6,000 Wikipedia webpages, while the same model achieves ~80% accuracy in a dataset of 13,000 classes that were not included in the training set.