 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Conditional Relation Networks for Multimodal Video Question Answering
Paper and Code

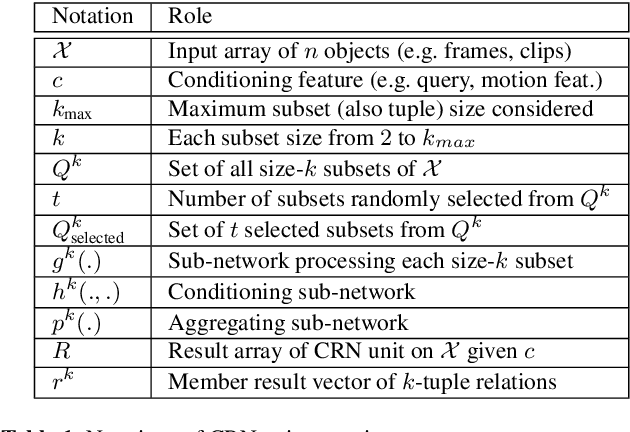

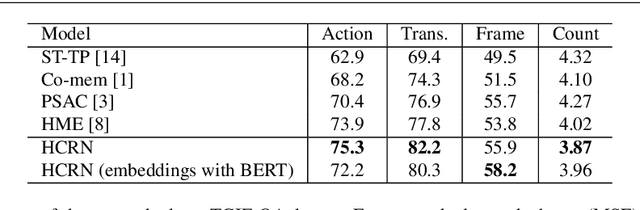
Video QA challenges modelers in multiple fronts. Modeling video necessitates building not only spatio-temporal models for the dynamic visual channel but also multimodal structures for associated information channels such as subtitles or audio. Video QA adds at least two more layers of complexity - selecting relevant content for each channel in the context of the linguistic query, and composing spatio-temporal concepts and relations in response to the query. To address these requirements, we start with two insights: (a) content selection and relation construction can be jointly encapsulated into a conditional computational structure, and (b) video-length structures can be composed hierarchically. For (a) this paper introduces a general-reusable neural unit dubbed Conditional Relation Network (CRN) taking as input a set of tensorial objects and translating into a new set of objects that encode relations of the inputs. The generic design of CRN helps ease the common complex model building process of Video QA by simple block stacking with flexibility in accommodating input modalities and conditioning features across both different domains. As a result, we realize insight (b) by introducing Hierarchical Conditional Relation Networks (HCRN) for Video QA. The HCRN primarily aims at exploiting intrinsic properties of the visual content of a video and its accompanying channels in terms of compositionality, hierarchy, and near and far-term relation. HCRN is then applied for Video QA in two forms, short-form where answers are reasoned solely from the visual content, and long-form where associated information, such as subtitles, presented. Our rigorous evaluations show consistent improvements over SOTAs on well-studied benchmarks including large-scale real-world datasets such as TGIF-QA and TVQA, demonstrating the strong capabilities of our CRN unit and the HCRN for complex domains such as Video QA.