Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgehinglishNorm -- A Corpus of Hindi-English Code Mixed Sentences for Text Normalization
Paper and Code
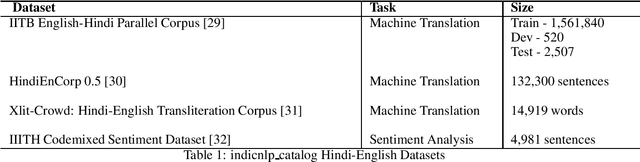
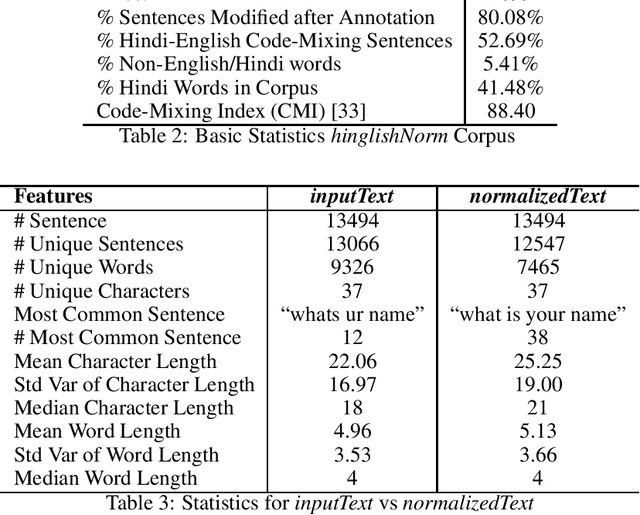
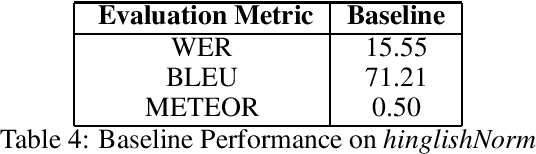
We present hinglishNorm -- a human annotated corpus of Hindi-English code-mixed sentences for text normalization task. Each sentence in the corpus is aligned to its corresponding human annotated normalized form. To the best of our knowledge, there is no corpus of Hindi-English code-mixed sentences for text normalization task that is publicly available. Our work is the first attempt in this direction. The corpus contains 13494 parallel segments. Further, we present baseline normalization results on this corpus. We obtain a Word Error Rate (WER) of 15.55, BiLingual Evaluation Understudy (BLEU) score of 71.2, and Metric for Evaluation of Translation with Explicit ORdering (METEOR) score of 0.50.
* Accepted in COLING2020 industry track, 8 pages (including
references), 4 tables
View paper on