 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting ESG topics using domain-specific language models and data augmentation approaches
Paper and Code
Oct 16, 2020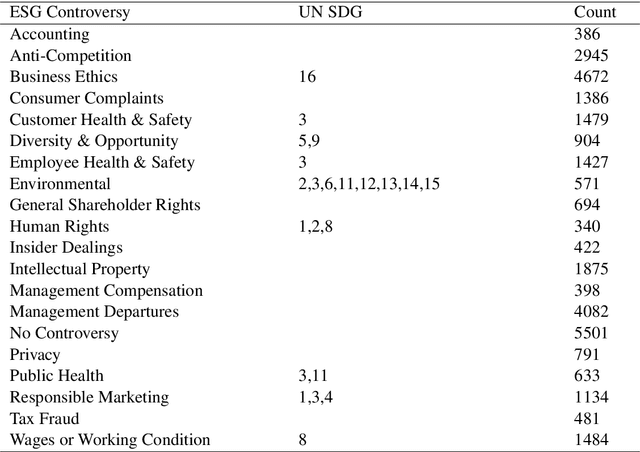

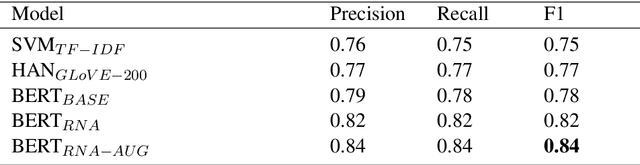
Despite recent advances in deep learning-based language modelling, many natural language processing (NLP) tasks in the financial domain remain challenging due to the paucity of appropriately labelled data. Other issues that can limit task performance are differences in word distribution between the general corpora - typically used to pre-train language models - and financial corpora, which often exhibit specialized language and symbology. Here, we investigate two approaches that may help to mitigate these issues. Firstly, we experiment with further language model pre-training using large amounts of in-domain data from business and financial news. We then apply augmentation approaches to increase the size of our dataset for model fine-tuning. We report our findings on an Environmental, Social and Governance (ESG) controversies dataset and demonstrate that both approaches are beneficial to accuracy in classification tasks.