 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Communication Lower Bounds for Distributed Optimisation
Paper and Code
Oct 16, 2020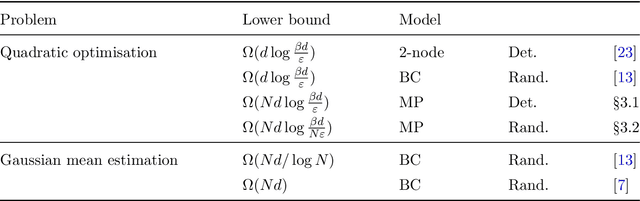

Motivated by the interest in communication-efficient methods for distributed machine learning, we consider the communication complexity of minimising a sum of $d$-dimensional functions $\sum_{i = 1}^N f_i (x)$, where each function $f_i$ is held by a one of the $N$ different machines. Such tasks arise naturally in large-scale optimisation, where a standard solution is to apply variants of (stochastic) gradient descent. As our main result, we show that $\Omega( Nd \log d / \varepsilon)$ bits in total need to be communicated between the machines to find an additive $\epsilon$-approximation to the minimum of $\sum_{i = 1}^N f_i (x)$. The results holds for deterministic algorithms, and randomised algorithms under some restrictions on the parameter values. Importantly, our lower bounds require no assumptions on the structure of the algorithm, and are matched within constant factors for strongly convex objectives by a new variant of quantised gradient descent. The lower bounds are obtained by bringing over tools from communication complexity to distributed optimisation, an approach we hope will find further use in future.