 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Sequence Labeling vs. Clause Classification for English Emotion Stimulus Detection
Paper and Code
Nov 09, 2020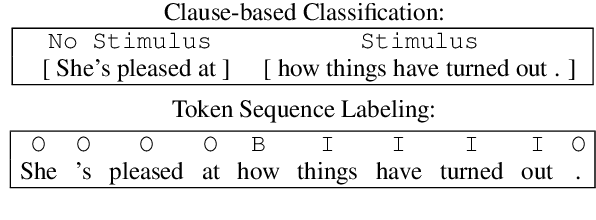

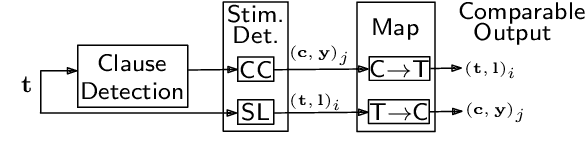
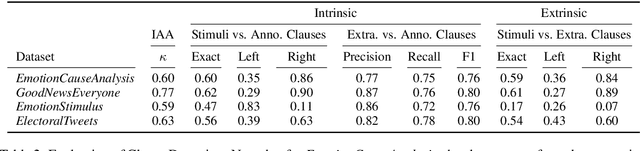
Emotion stimulus detection is the task of finding the cause of an emotion in a textual description, similar to target or aspect detection for sentiment analysis. Previous work approached this in three ways, namely (1) as text classification into an inventory of predefined possible stimuli ("Is the stimulus category A or B?"), (2) as sequence labeling of tokens ("Which tokens describe the stimulus?"), and (3) as clause classification ("Does this clause contain the emotion stimulus?"). So far, setting (3) has been evaluated broadly on Mandarin and (2) on English, but no comparison has been performed. Therefore, we aim to answer whether clause classification or sequence labeling is better suited for emotion stimulus detection in English. To accomplish that, we propose an integrated framework which enables us to evaluate the two different approaches comparably, implement models inspired by state-of-the-art approaches in Mandarin, and test them on four English data sets from different domains. Our results show that sequence labeling is superior on three out of four datasets, in both clause-based and sequence-based evaluation. The only case in which clause classification performs better is one data set with a high density of clause annotations. Our error analysis further confirms quantitatively and qualitatively that clauses are not the appropriate stimulus unit in English.