 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Word Representations for Tunisian Sentiment Analysis
Paper and Code
Oct 14, 2020
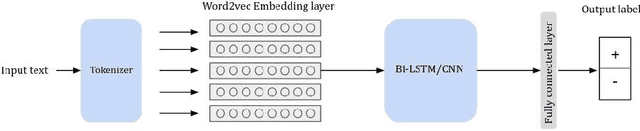
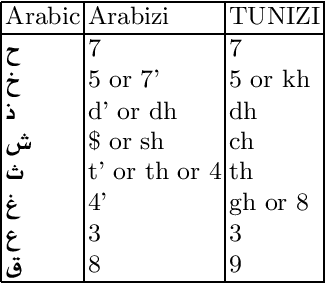
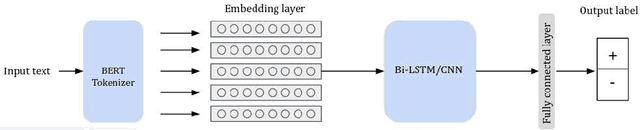
Tunisians on social media tend to express themselves in their local dialect using Latin script (TUNIZI). This raises an additional challenge to the process of exploring and recognizing online opinions. To date, very little work has addressed TUNIZI sentiment analysis due to scarce resources for training an automated system. In this paper, we focus on the Tunisian dialect sentiment analysis used on social media. Most of the previous work used machine learning techniques combined with handcrafted features. More recently, Deep Neural Networks were widely used for this task, especially for the English language. In this paper, we explore the importance of various unsupervised word representations (word2vec, BERT) and we investigate the use of Convolutional Neural Networks and Bidirectional Long Short-Term Memory. Without using any kind of handcrafted features, our experimental results on two publicly available datasets showed comparable performances to other languages.