 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging the Capabilities of Connected and Autonomous Vehicles and Multi-Agent Reinforcement Learning to Mitigate Highway Bottleneck Congestion
Paper and Code
Oct 12, 2020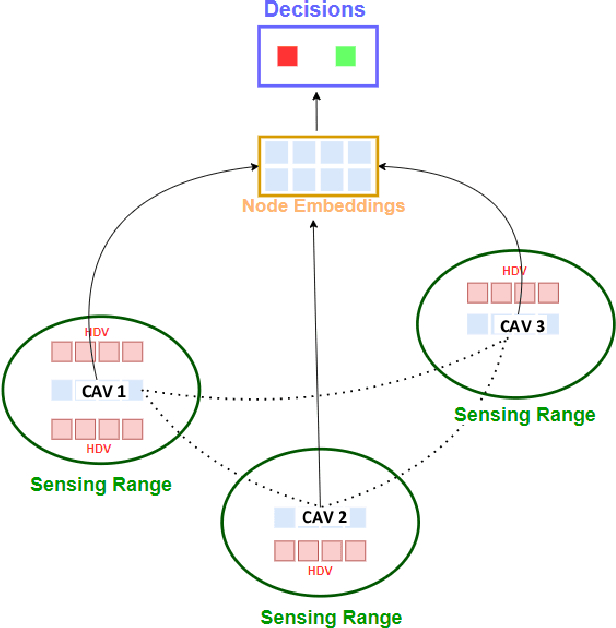
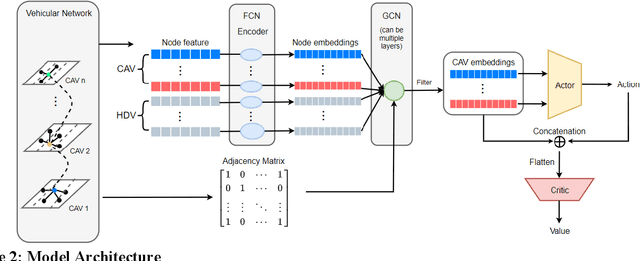
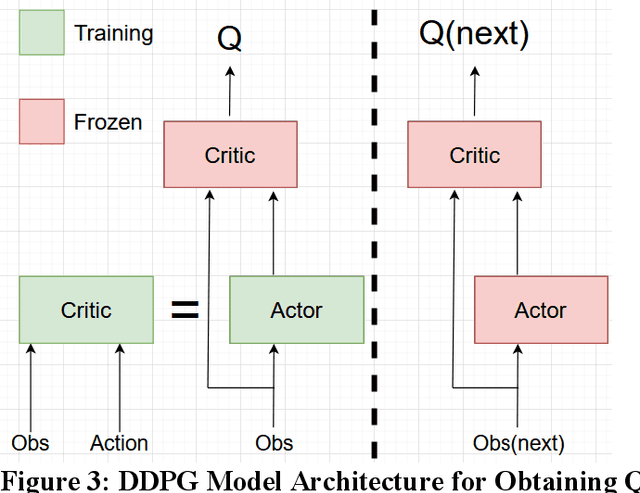

Active Traffic Management strategies are often adopted in real-time to address such sudden flow breakdowns. When queuing is imminent, Speed Harmonization (SH), which adjusts speeds in upstream traffic to mitigate traffic showckwaves downstream, can be applied. However, because SH depends on driver awareness and compliance, it may not always be effective in mitigating congestion. The use of multiagent reinforcement learning for collaborative learning, is a promising solution to this challenge. By incorporating this technique in the control algorithms of connected and autonomous vehicle (CAV), it may be possible to train the CAVs to make joint decisions that can mitigate highway bottleneck congestion without human driver compliance to altered speed limits. In this regard, we present an RL-based multi-agent CAV control model to operate in mixed traffic (both CAVs and human-driven vehicles (HDVs)). The results suggest that even at CAV percent share of corridor traffic as low as 10%, CAVs can significantly mitigate bottlenecks in highway traffic. Another objective was to assess the efficacy of the RL-based controller vis-\`a-vis that of the rule-based controller. In addressing this objective, we duly recognize that one of the main challenges of RL-based CAV controllers is the variety and complexity of inputs that exist in the real world, such as the information provided to the CAV by other connected entities and sensed information. These translate as dynamic length inputs which are difficult to process and learn from. For this reason, we propose the use of Graphical Convolution Networks (GCN), a specific RL technique, to preserve information network topology and corresponding dynamic length inputs. We then use this, combined with Deep Deterministic Policy Gradient (DDPG), to carry out multi-agent training for congestion mitigation using the CAV controllers.