 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep RL With Information Constrained Policies: Generalization in Continuous Control
Paper and Code
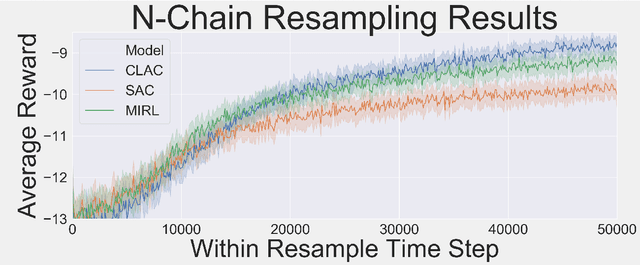
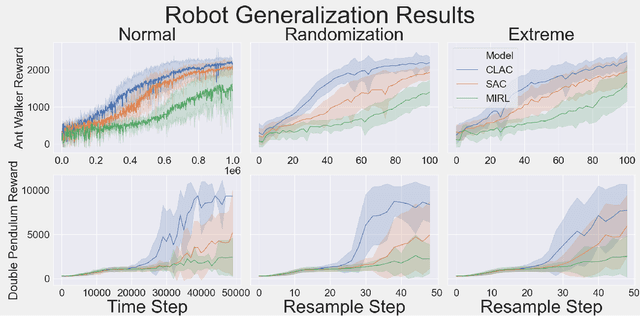
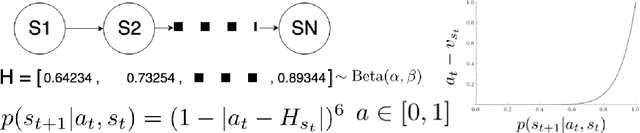
Biological agents learn and act intelligently in spite of a highly limited capacity to process and store information. Many real-world problems involve continuous control, which represents a difficult task for artificial intelligence agents. In this paper we explore the potential learning advantages a natural constraint on information flow might confer onto artificial agents in continuous control tasks. We focus on the model-free reinforcement learning (RL) setting and formalize our approach in terms of an information-theoretic constraint on the complexity of learned policies. We show that our approach emerges in a principled fashion from the application of rate-distortion theory. We implement a novel Capacity-Limited Actor-Critic (CLAC) algorithm and situate it within a broader family of RL algorithms such as the Soft Actor Critic (SAC) and Mutual Information Reinforcement Learning (MIRL) algorithm. Our experiments using continuous control tasks show that compared to alternative approaches, CLAC offers improvements in generalization between training and modified test environments. This is achieved in the CLAC model while displaying the high sample efficiency of similar methods.