 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRank and run-time aware compression of NLP Applications
Paper and Code
Oct 06, 2020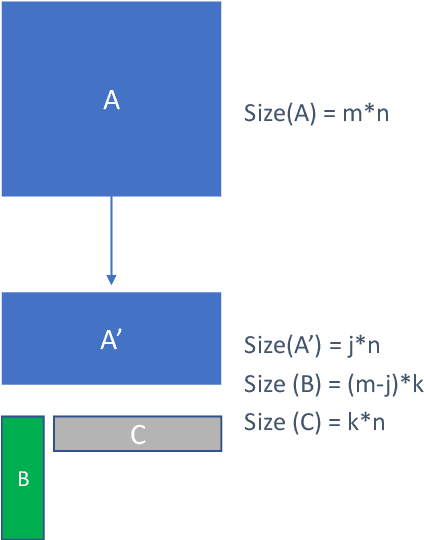
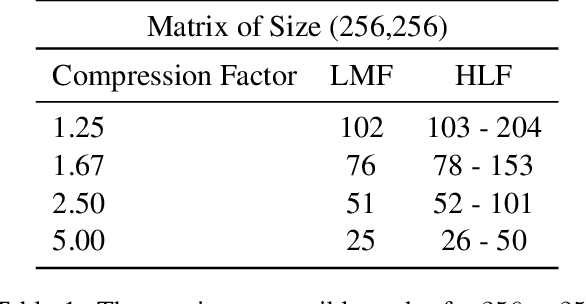
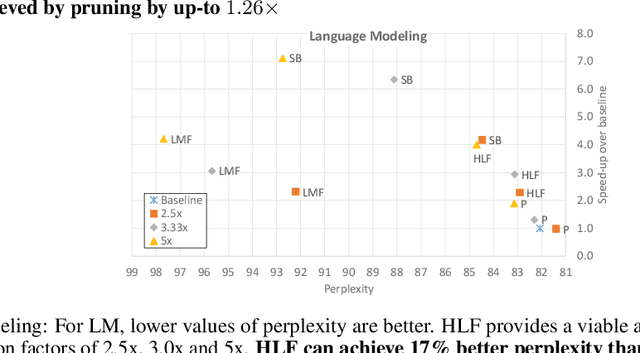
Sequence model based NLP applications can be large. Yet, many applications that benefit from them run on small devices with very limited compute and storage capabilities, while still having run-time constraints. As a result, there is a need for a compression technique that can achieve significant compression without negatively impacting inference run-time and task accuracy. This paper proposes a new compression technique called Hybrid Matrix Factorization that achieves this dual objective. HMF improves low-rank matrix factorization (LMF) techniques by doubling the rank of the matrix using an intelligent hybrid-structure leading to better accuracy than LMF. Further, by preserving dense matrices, it leads to faster inference run-time than pruning or structure matrix based compression technique. We evaluate the impact of this technique on 5 NLP benchmarks across multiple tasks (Translation, Intent Detection, Language Modeling) and show that for similar accuracy values and compression factors, HMF can achieve more than 2.32x faster inference run-time than pruning and 16.77% better accuracy than LMF.