 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generalized Constraint Approach to Bilingual Dictionary Induction for Low-Resource Language Families
Paper and Code
Oct 05, 2020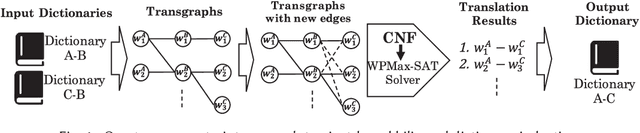



The lack or absence of parallel and comparable corpora makes bilingual lexicon extraction a difficult task for low-resource languages. The pivot language and cognate recognition approaches have been proven useful for inducing bilingual lexicons for such languages. We propose constraint-based bilingual lexicon induction for closely-related languages by extending constraints from the recent pivot-based induction technique and further enabling multiple symmetry assumption cycles to reach many more cognates in the transgraph. We further identify cognate synonyms to obtain many-to-many translation pairs. This paper utilizes four datasets: one Austronesian low-resource language and three Indo-European high-resource languages. We use three constraint-based methods from our previous work, the Inverse Consultation method and translation pairs generated from the Cartesian product of input dictionaries as baselines. We evaluate our result using the metrics of precision, recall and F-score. Our customizable approach allows the user to conduct cross-validation to predict the optimal hyperparameters (cognate threshold and cognate synonym threshold) with various combinations of heuristics and the number of symmetry assumption cycles to gain the highest F-score. Our proposed methods have statistically significant improvement of precision and F-score compared to our previous constraint-based methods. The results show that our method demonstrates the potential to complement other bilingual dictionary creation methods like word alignment models using parallel corpora for high-resource languages while well handling low-resource languages.