 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Precision Ensemble: Self-Knowledge Distillation for Quantized Deep Neural Networks
Paper and Code

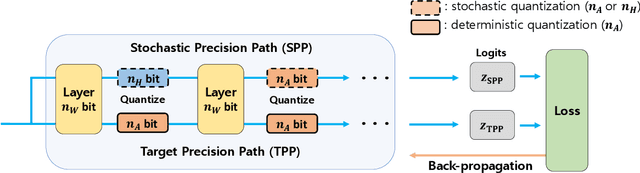
The quantization of deep neural networks (QDNNs) has been actively studied for deployment in edge devices. Recent studies employ the knowledge distillation (KD) method to improve the performance of quantized networks. In this study, we propose stochastic precision ensemble training for QDNNs (SPEQ). SPEQ is a knowledge distillation training scheme; however, the teacher is formed by sharing the model parameters of the student network. We obtain the soft labels of the teacher by changing the bit precision of the activation stochastically at each layer of the forward-pass computation. The student model is trained with these soft labels to reduce the activation quantization noise. The cosine similarity loss is employed, instead of the KL-divergence, for KD training. As the teacher model changes continuously by random bit-precision assignment, it exploits the effect of stochastic ensemble KD. SPEQ outperforms the existing quantization training methods in various tasks, such as image classification, question-answering, and transfer learning without the need for cumbersome teacher networks.