 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework of Learning Through Empirical Gain Maximization
Paper and Code
Sep 29, 2020
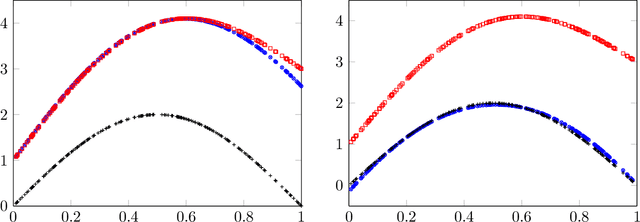
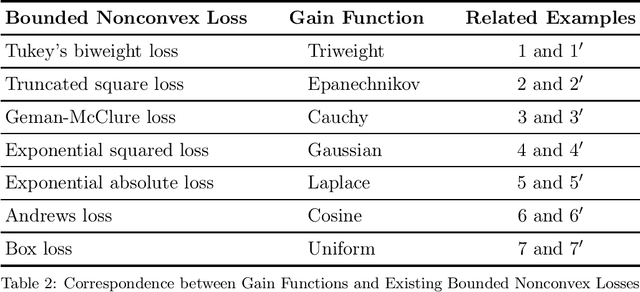
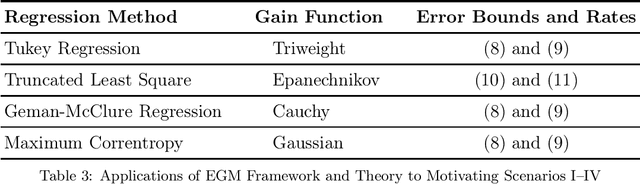
We develop in this paper a framework of empirical gain maximization (EGM) to address the robust regression problem where heavy-tailed noise or outliers may present in the response variable. The idea of EGM is to approximate the density function of the noise distribution instead of approximating the truth function directly as usual. Unlike the classical maximum likelihood estimation that encourages equal importance of all observations and could be problematic in the presence of abnormal observations, EGM schemes can be interpreted from a minimum distance estimation viewpoint and allow the ignorance of those observations. Furthermore, it is shown that several well-known robust nonconvex regression paradigms, such as Tukey regression and truncated least square regression, can be reformulated into this new framework. We then develop a learning theory for EGM, by means of which a unified analysis can be conducted for these well-established but not fully-understood regression approaches. Resulting from the new framework, a novel interpretation of existing bounded nonconvex loss functions can be concluded. Within this new framework, the two seemingly irrelevant terminologies, the well-known Tukey's biweight loss for robust regression and the triweight kernel for nonparametric smoothing, are closely related. More precisely, it is shown that the Tukey's biweight loss can be derived from the triweight kernel. Similarly, other frequently employed bounded nonconvex loss functions in machine learning such as the truncated square loss, the Geman-McClure loss, and the exponential squared loss can also be reformulated from certain smoothing kernels in statistics. In addition, the new framework enables us to devise new bounded nonconvex loss functions for robust learning.