 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA little goes a long way: Improving toxic language classification despite data scarcity
Paper and Code
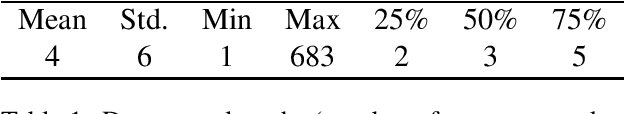

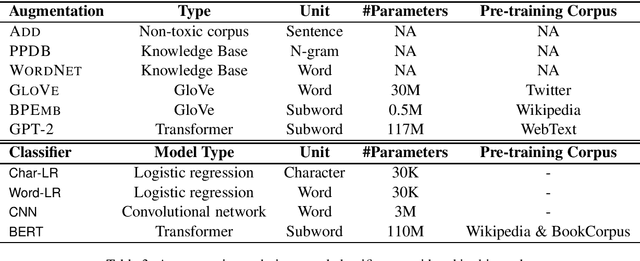
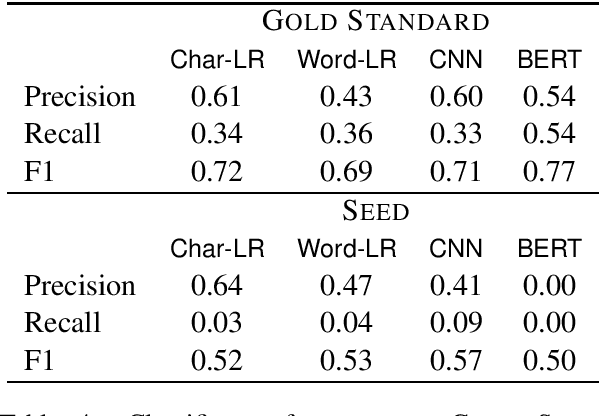
Detection of some types of toxic language is hampered by extreme scarcity of labeled training data. Data augmentation - generating new synthetic data from a labeled seed dataset - can help. The efficacy of data augmentation on toxic language classification has not been fully explored. We present the first systematic study on how data augmentation techniques impact performance across toxic language classifiers, ranging from shallow logistic regression architectures to BERT - a state-of-the-art pre-trained Transformer network. We compare the performance of eight techniques on very scarce seed datasets. We show that while BERT performed the best, shallow classifiers performed comparably when trained on data augmented with a combination of three techniques, including GPT-2-generated sentences. We discuss the interplay of performance and computational overhead, which can inform the choice of techniques under different constraints.