 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Non-Unique Segmentation with Reward-Penalty Dice Loss
Paper and Code
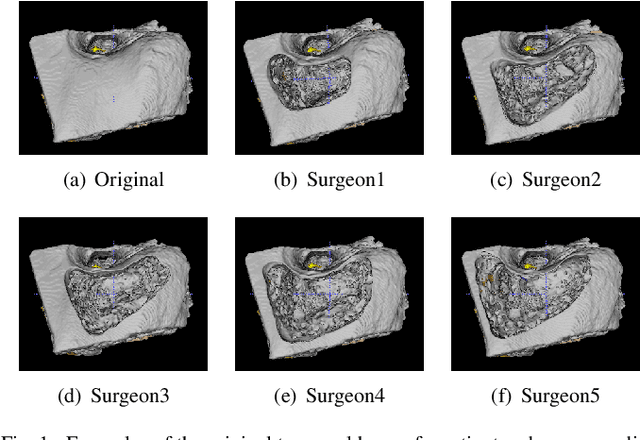
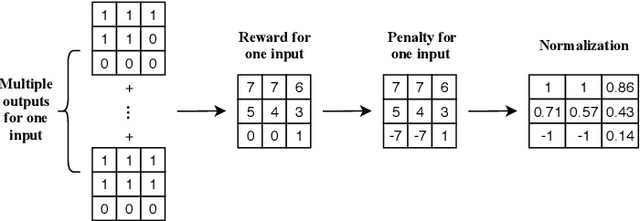
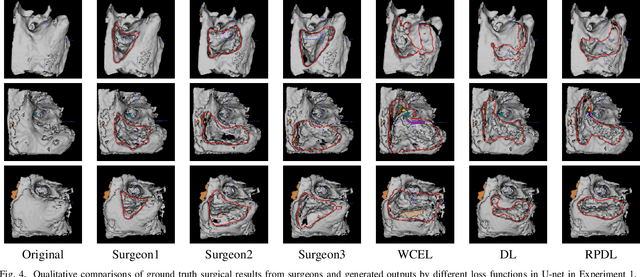
Semantic segmentation is one of the key problems in the field of computer vision, as it enables computer image understanding. However, most research and applications of semantic segmentation focus on addressing unique segmentation problems, where there is only one gold standard segmentation result for every input image. This may not be true in some problems, e.g., medical applications. We may have non-unique segmentation annotations as different surgeons may perform successful surgeries for the same patient in slightly different ways. To comprehensively learn non-unique segmentation tasks, we propose the reward-penalty Dice loss (RPDL) function as the optimization objective for deep convolutional neural networks (DCNN). RPDL is capable of helping DCNN learn non-unique segmentation by enhancing common regions and penalizing outside ones. Experimental results show that RPDL improves the performance of DCNN models by up to 18.4% compared with other loss functions on our collected surgical dataset.