 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditionally Adaptive Multi-Task Learning: Improving Transfer Learning in NLP Using Fewer Parameters & Less Data
Paper and Code
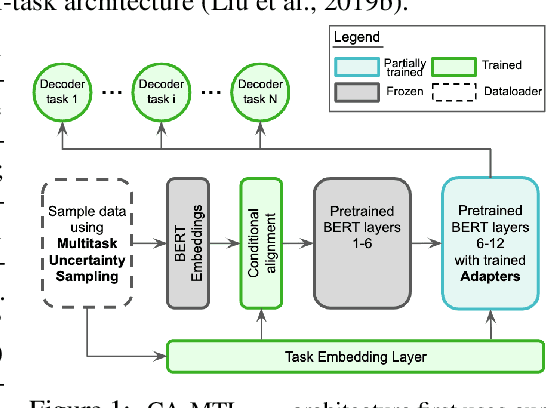
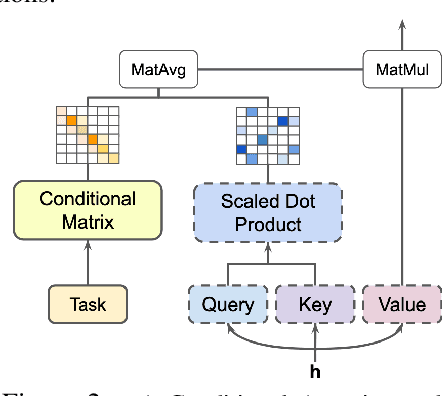
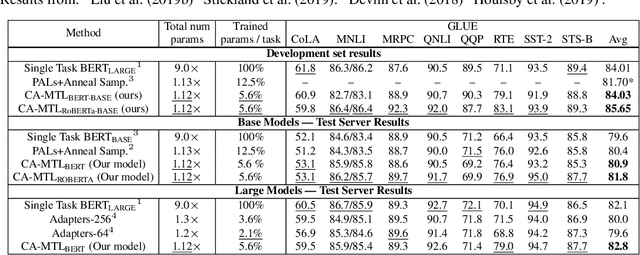
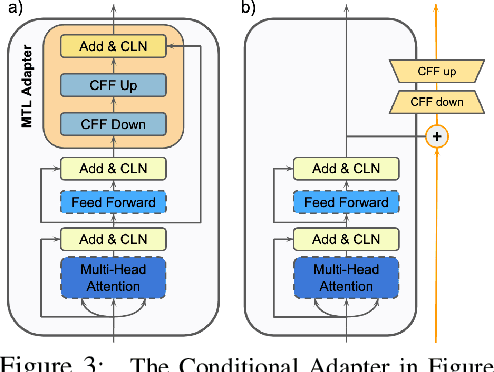
Multi-Task Learning (MTL) has emerged as a promising approach for transferring learned knowledge across different tasks. However, multi-task learning must deal with challenges such as: overfitting to low resource tasks, catastrophic forgetting, and negative task transfer, or learning interference. Additionally, in Natural Language Processing (NLP), MTL alone has typically not reached the performance level possible through per-task fine-tuning of pretrained models. However, many fine-tuning approaches are both parameter inefficient, e.g. potentially involving one new model per task, and highly susceptible to losing knowledge acquired during pretraining. We propose a novel transformer based architecture consisting of a new conditional attention mechanism as well as a set of task conditioned modules that facilitate weight sharing. Through this construction we achieve more efficient parameter sharing and mitigate forgetting by keeping half of the weights of a pretrained model fixed. We also use a new multi-task data sampling strategy to mitigate the negative effects of data imbalance across tasks. Using this approach we are able to surpass single-task fine-tuning methods while being parameter and data efficient. With our base model, we attain 2.2% higher performance compared to a full fine-tuned BERT large model on the GLUE benchmark, adding only 5.6% more trained parameters per task (whereas naive fine-tuning potentially adds 100% of the trained parameters per task) and needing only 64.6% of the data. We show that a larger variant of our single multi-task model approach performs competitively across 26 NLP tasks and yields state-of-the-art results on a number of test and development sets.