 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Convolution Kernel for Artificial Neural Networks
Paper and Code
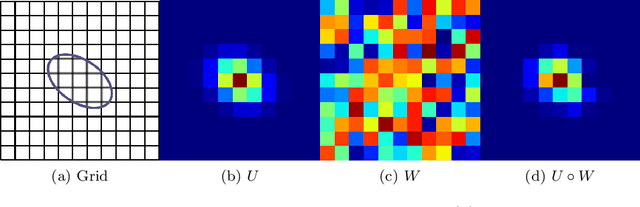
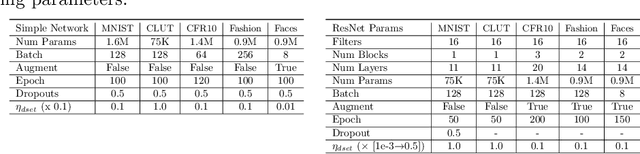

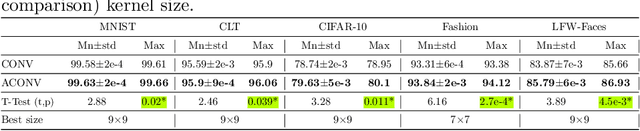
Many deep neural networks are built by using stacked convolutional layers of fixed and single size (often 3$\times$3) kernels. This paper describes a method for training the size of convolutional kernels to provide varying size kernels in a single layer. The method utilizes a differentiable, and therefore backpropagation-trainable Gaussian envelope which can grow or shrink in a base grid. Our experiments compared the proposed adaptive layers to ordinary convolution layers in a simple two-layer network, a deeper residual network, and a U-Net architecture. The results in the popular image classification datasets such as MNIST, MNIST-CLUTTERED, CIFAR-10, Fashion, and ``Faces in the Wild'' showed that the adaptive kernels can provide statistically significant improvements on ordinary convolution kernels. A segmentation experiment in the Oxford-Pets dataset demonstrated that replacing a single ordinary convolution layer in a U-shaped network with a single 7$\times$7 adaptive layer can improve its learning performance and ability to generalize.