 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Bi-LSTM Performance for Indonesian Sentiment Analysis Using Paragraph Vector
Paper and Code
Sep 12, 2020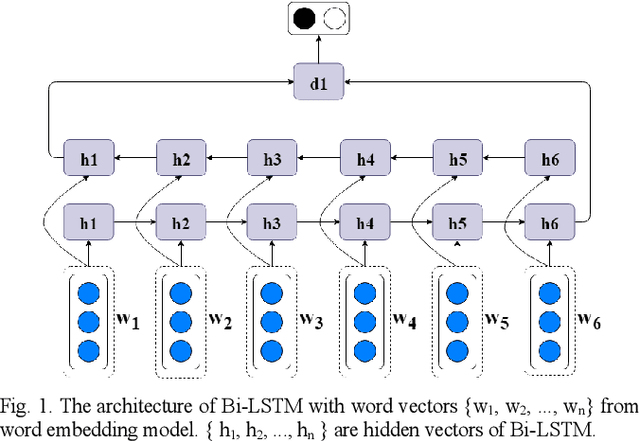
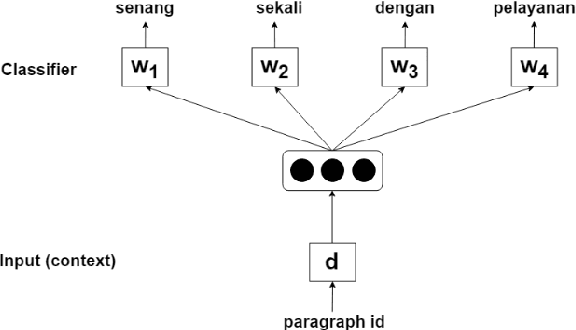
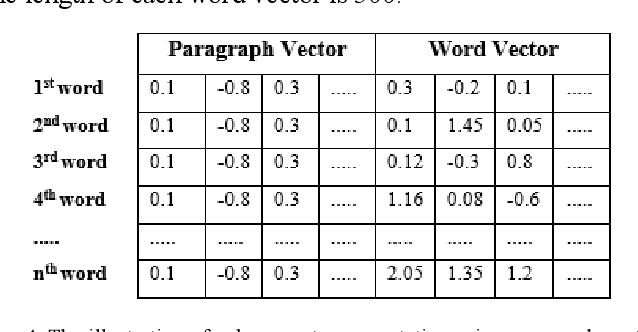
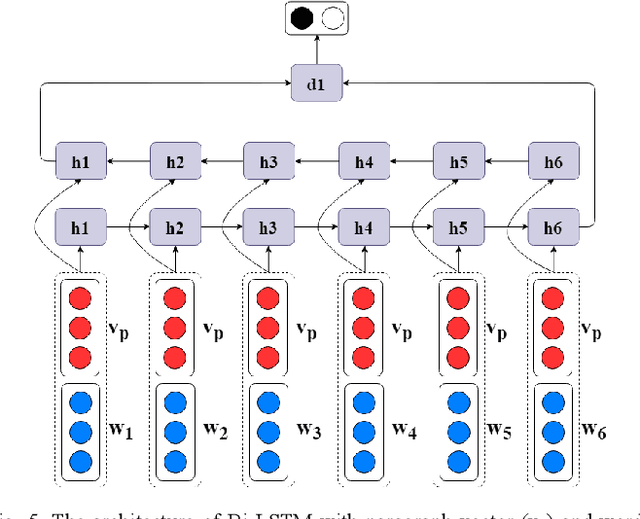
Bidirectional Long Short-Term Memory Network (Bi-LSTM) has shown promising performance in sentiment classification task. It processes inputs as sequence of information. Due to this behavior, sentiment predictions by Bi-LSTM were influenced by words sequence and the first or last phrases of the texts tend to have stronger features than other phrases. Meanwhile, in the problem scope of Indonesian sentiment analysis, phrases that express the sentiment of a document might not appear in the first or last part of the document that can lead to incorrect sentiment classification. To this end, we propose the using of an existing document representation method called paragraph vector as additional input features for Bi-LSTM. This vector provides information context of the document for each sequence processing. The paragraph vector is simply concatenated to each word vector of the document. This representation also helps to differentiate ambiguous Indonesian words. Bi-LSTM and paragraph vector were previously used as separate methods. Combining the two methods has shown a significant performance improvement of Indonesian sentiment analysis model. Several case studies on testing data showed that the proposed method can handle the sentiment phrases position problem encountered by Bi-LSTM.