 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Robustness to Model Inversion Attacks via Mutual Information Regularization
Paper and Code
Sep 22, 2020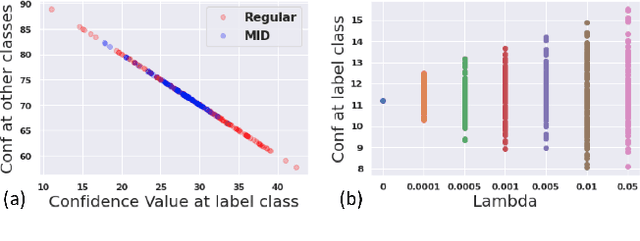


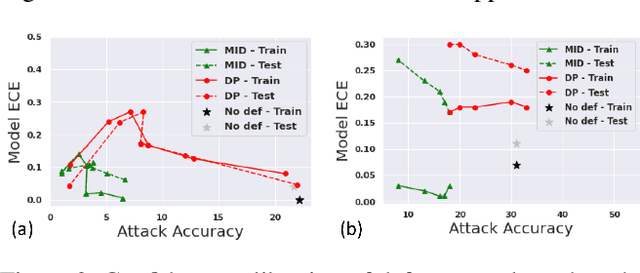
This paper studies defense mechanisms against model inversion (MI) attacks -- a type of privacy attacks aimed at inferring information about the training data distribution given the access to a target machine learning model. Existing defense mechanisms rely on model-specific heuristics or noise injection. While being able to mitigate attacks, existing methods significantly hinder model performance. There remains a question of how to design a defense mechanism that is applicable to a variety of models and achieves better utility-privacy tradeoff. In this paper, we propose the Mutual Information Regularization based Defense (MID) against MI attacks. The key idea is to limit the information about the model input contained in the prediction, thereby limiting the ability of an adversary to infer the private training attributes from the model prediction. Our defense principle is model-agnostic and we present tractable approximations to the regularizer for linear regression, decision trees, and neural networks, which have been successfully attacked by prior work if not attached with any defenses. We present a formal study of MI attacks by devising a rigorous game-based definition and quantifying the associated information leakage. Our theoretical analysis sheds light on the inefficacy of DP in defending against MI attacks, which has been empirically observed in several prior works. Our experiments demonstrate that MID leads to state-of-the-art performance for a variety of MI attacks, target models and datasets.