Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiaoNing at SemEval-2020 Task 4: Commonsense Validation and Explanation system based on ensemble of language model
Paper and Code
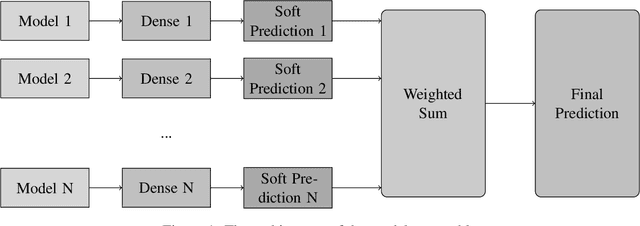


In this paper, we present language model system submitted to SemEval-2020 Task 4 competition: "Commonsense Validation and Explanation". We participate in two subtasks for subtask A: validation and subtask B: Explanation. We implemented with transfer learning using pretrained language models (BERT, XLNet, RoBERTa, and ALBERT) and fine-tune them on this task. Then we compared their characteristics in this task to help future researchers understand and use these models more properly. The ensembled model better solves this problem, making the model's accuracy reached 95.9% on subtask A, which just worse than human's by only 3% accuracy.
View paper on