Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBio-inspired Structure Identification in Language Embeddings
Paper and Code
Sep 15, 2020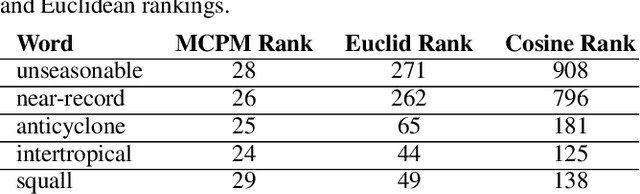
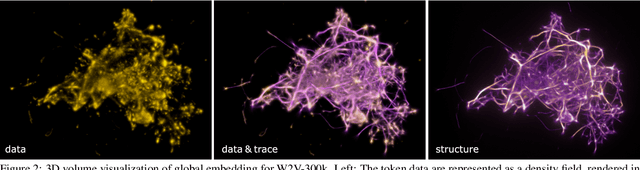

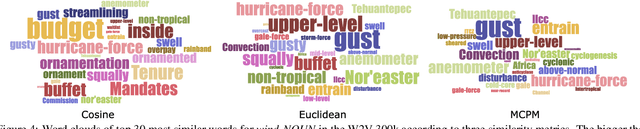
Word embeddings are a popular way to improve downstream performances in contemporary language modeling. However, the underlying geometric structure of the embedding space is not well understood. We present a series of explorations using bio-inspired methodology to traverse and visualize word embeddings, demonstrating evidence of discernible structure. Moreover, our model also produces word similarity rankings that are plausible yet very different from common similarity metrics, mainly cosine similarity and Euclidean distance. We show that our bio-inspired model can be used to investigate how different word embedding techniques result in different semantic outputs, which can emphasize or obscure particular interpretations in textual data.
* 7 pages, 8 figures, 2 tables, Visualisation for the Digital
Humanities 2020. Comments: Fixed white spaces in abstract
View paper on