 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn sampling from data with duplicate records
Paper and Code
Aug 24, 2020
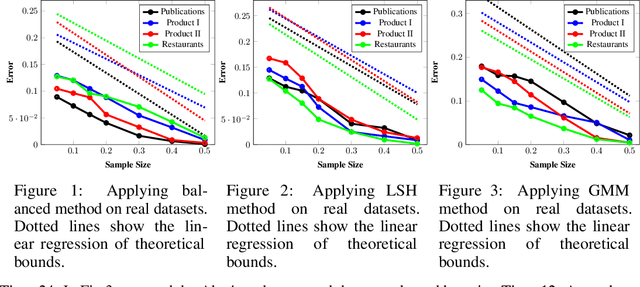
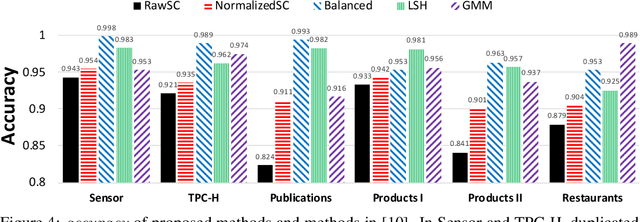
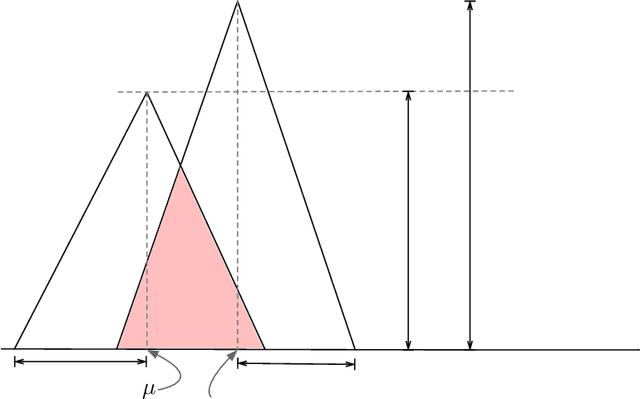
Data deduplication is the task of detecting records in a database that correspond to the same real-world entity. Our goal is to develop a procedure that samples uniformly from the set of entities present in the database in the presence of duplicates. We accomplish this by a two-stage process. In the first step, we estimate the frequencies of all the entities in the database. In the second step, we use rejection sampling to obtain a (approximately) uniform sample from the set of entities. However, efficiently estimating the frequency of all the entities is a non-trivial task and not attainable in the general case. Hence, we consider various natural properties of the data under which such frequency estimation (and consequently uniform sampling) is possible. Under each of those assumptions, we provide sampling algorithms and give proofs of the complexity (both statistical and computational) of our approach. We complement our study by conducting extensive experiments on both real and synthetic datasets.