 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompiling ONNX Neural Network Models Using MLIR
Paper and Code
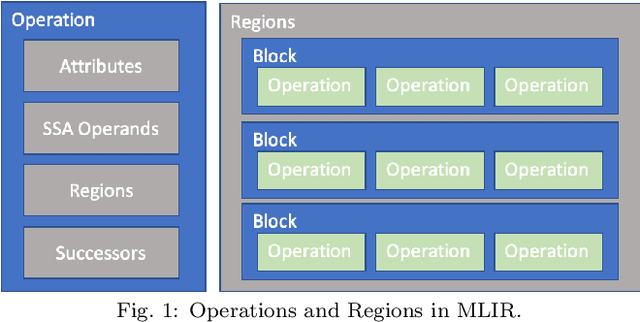

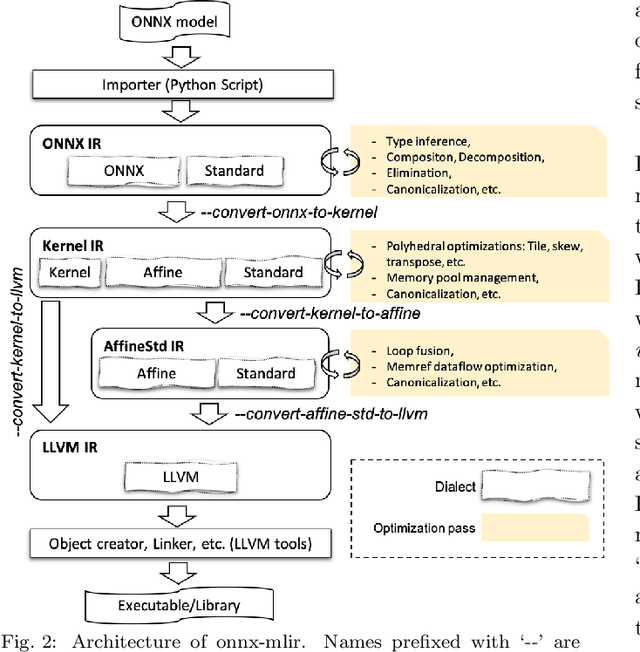
Deep neural network models are becoming increasingly popular and have been used in various tasks such as computer vision, speech recognition, and natural language processing. Machine learning models are commonly trained in a resource-rich environment and then deployed in a distinct environment such as high availability machines or edge devices. To assist the portability of models, the open-source community has proposed the Open Neural Network Exchange (ONNX) standard. In this paper, we present a high-level, preliminary report on our onnx-mlir compiler, which generates code for the inference of deep neural network models described in the ONNX format. Onnx-mlir is an open-source compiler implemented using the Multi-Level Intermediate Representation (MLIR) infrastructure recently integrated in the LLVM project. Onnx-mlir relies on the MLIR concept of dialects to implement its functionality. We propose here two new dialects: (1) an ONNX specific dialect that encodes the ONNX standard semantics, and (2) a loop-based dialect to provide for a common lowering point for all ONNX dialect operations. Each intermediate representation facilitates its own characteristic set of graph-level and loop-based optimizations respectively. We illustrate our approach by following several models through the proposed representations and we include some early optimization work and performance results.