 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDORY: Automatic End-to-End Deployment of Real-World DNNs on Low-Cost IoT MCUs
Paper and Code
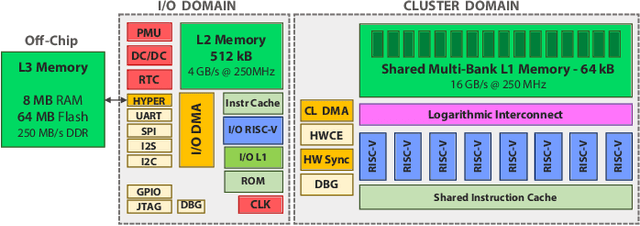


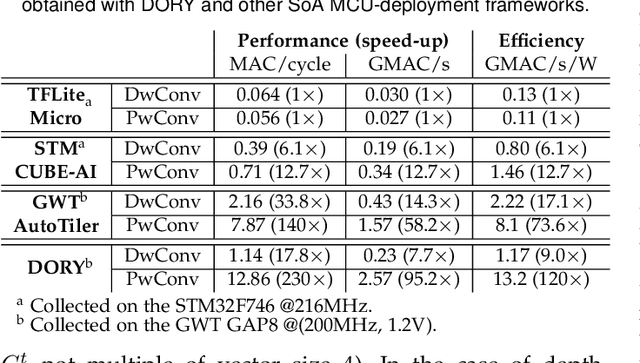
The deployment of Deep Neural Networks (DNNs) on end-nodes at the extreme edge of the Internet-of-Things is a critical enabler to support pervasive Deep Learning-enhanced applications. Low-Cost MCU-based end-nodes have limited on-chip memory and often replace caches with scratchpads, to reduce area overheads and increase energy efficiency -- requiring explicit DMA-based memory transfers between different levels of the memory hierarchy. Mapping modern DNNs on these systems requires aggressive topology-dependent tiling and double-buffering. In this work, we propose DORY (Deployment Oriented to memoRY) - an automatic tool to deploy DNNs on low cost MCUs with typically less than 1MB of on-chip SRAM memory. DORY abstracts tiling as a Constraint Programming (CP) problem: it maximizes L1 memory utilization under the topological constraints imposed by each DNN layer. Then, it generates ANSI C code to orchestrate off- and on-chip transfers and computation phases. Furthermore, to maximize speed, DORY augments the CP formulation with heuristics promoting performance-effective tile sizes. As a case study for DORY, we target GreenWaves Technologies GAP8, one of the most advanced parallel ultra-low power MCU-class devices on the market. On this device, DORY achieves up to 2.5x better MAC/cycle than the GreenWaves proprietary software solution and 18.1x better than the state-of-the-art result on an STM32-F746 MCU on single layers. Using our tool, GAP-8 can perform end-to-end inference of a 1.0-MobileNet-128 network consuming just 63 pJ/MAC on average @ 4.3 fps - 15.4x better than an STM32-F746. We release all our developments - the DORY framework, the optimized backend kernels, and the related heuristics - as open-source software.