 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Error Rate Estimation Without ASR Output: e-WER2
Paper and Code
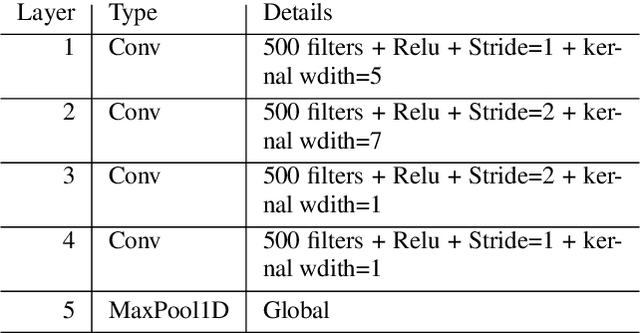
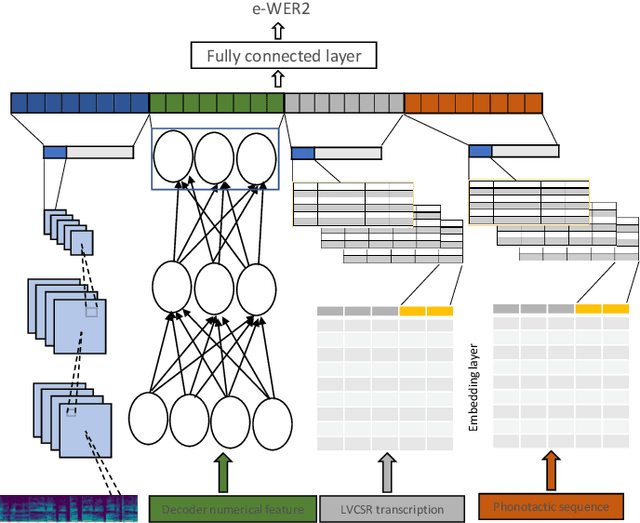
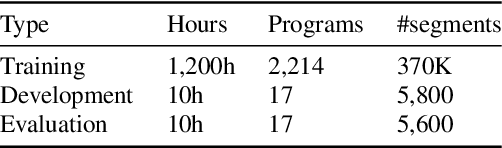
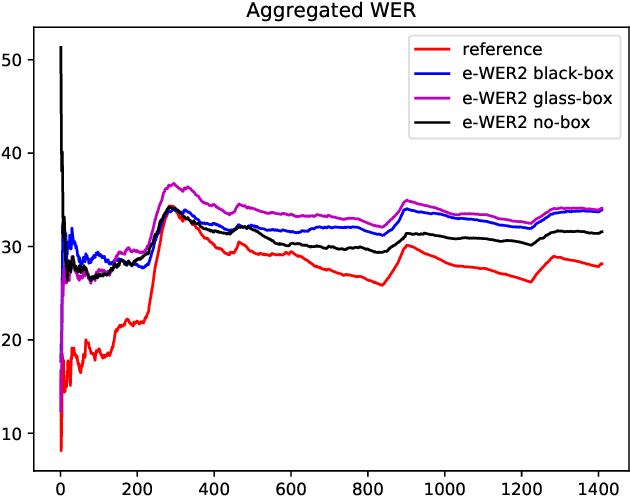
Measuring the performance of automatic speech recognition (ASR) systems requires manually transcribed data in order to compute the word error rate (WER), which is often time-consuming and expensive. In this paper, we continue our effort in estimating WER using acoustic, lexical and phonotactic features. Our novel approach to estimate the WER uses a multistream end-to-end architecture. We report results for systems using internal speech decoder features (glass-box), systems without speech decoder features (black-box), and for systems without having access to the ASR system (no-box). The no-box system learns joint acoustic-lexical representation from phoneme recognition results along with MFCC acoustic features to estimate WER. Considering WER per sentence, our no-box system achieves 0.56 Pearson correlation with the reference evaluation and 0.24 root mean square error (RMSE) across 1,400 sentences. The estimated overall WER by e-WER2 is 30.9% for a three hours test set, while the WER computed using the reference transcriptions was 28.5%.