 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Tera-Scale Similarity Search with MPI: Provably Efficient Similarity Search over billions without a Single Distance Computation
Paper and Code
Aug 17, 2020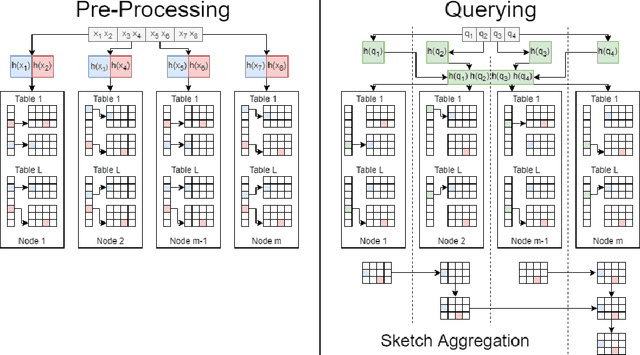

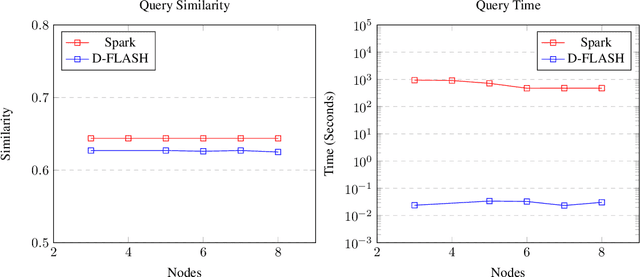
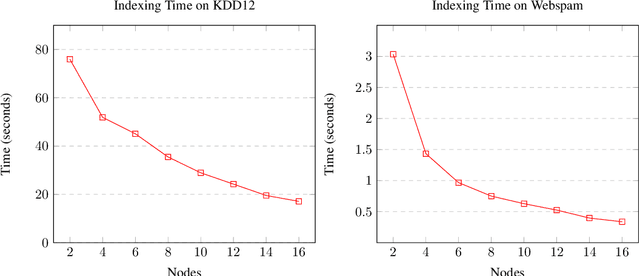
We present SLASH (Sketched LocAlity Sensitive Hashing), an MPI (Message Passing Interface) based distributed system for approximate similarity search over terabyte scale datasets. SLASH provides a multi-node implementation of the popular LSH (locality sensitive hashing) algorithm, which is generally implemented on a single machine. We show how we can append the LSH algorithm with heavy hitters sketches to provably solve the (high) similarity search problem without a single distance computation. Overall, we mathematically show that, under realistic data assumptions, we can identify the near-neighbor of a given query $q$ in sub-linear ($ \ll O(n)$) number of simple sketch aggregation operations only. To make such a system practical, we offer a novel design and sketching solution to reduce the inter-machine communication overheads exponentially. In a direct comparison on comparable hardware, SLASH is more than 10000x faster than the popular LSH package in PySpark. PySpark is a widely-adopted distributed implementation of the LSH algorithm for large datasets and is deployed in commercial platforms. In the end, we show how our system scale to Tera-scale Criteo dataset with more than 4 billion samples. SLASH can index this 2.3 terabyte data over 20 nodes in under an hour, with query times in a fraction of milliseconds. To the best of our knowledge, there is no open-source system that can index and perform a similarity search on Criteo with a commodity cluster.