 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRMDN: Flow-based Recurrent Mixture Density Network
Paper and Code
Aug 05, 2020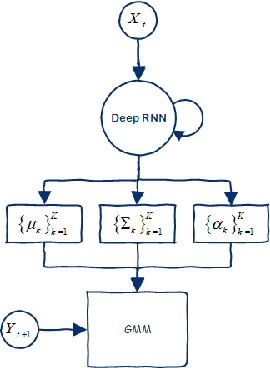
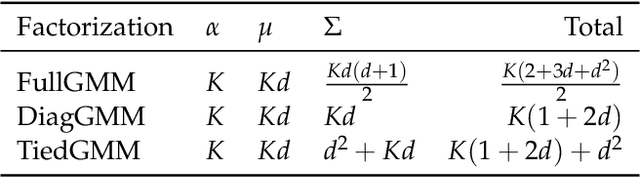
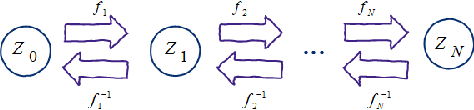
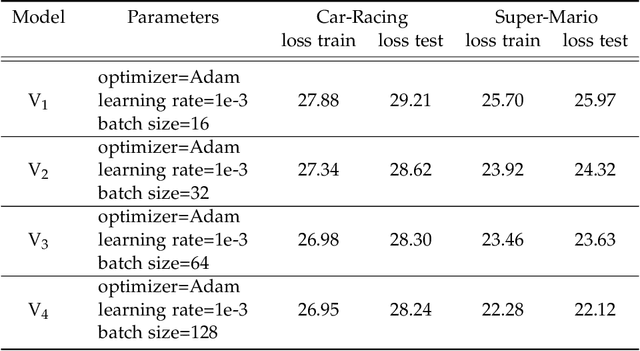
Recurrent Mixture Density Networks (RMDNs) are consisted of two main parts: a Recurrent Neural Network (RNN) and a Gaussian Mixture Model (GMM), in which a kind of RNN (almost LSTM) is used to find the parameters of a GMM in every time step. While available RMDNs have been faced with different difficulties. The most important of them is high$-$dimensional problems. Since estimating the covariance matrix for the high$-$dimensional problems is more difficult, due to existing correlation between dimensions and satisfying the positive definition condition. Consequently, the available methods have usually used RMDN with a diagonal covariance matrix for high$-$dimensional problems by supposing independence among dimensions. Hence, in this paper with inspiring a common approach in the literature of GMM, we consider a tied configuration for each precision matrix (inverse of the covariance matrix) in RMDN as $(\(\Sigma _k^{ - 1} = U{D_k}U\))$ to enrich GMM rather than considering a diagonal form for it. But due to simplicity, we assume $\(U\)$ be an Identity matrix and $\(D_k\)$ is a specific diagonal matrix for $\(k^{th}\)$ component. Until now, we only have a diagonal matrix and it does not differ with available diagonal RMDNs. Besides, Flow$-$based neural networks are a new group of generative models that are able to transform a distribution to a simpler distribution and vice versa, through a sequence of invertible functions. Therefore, we applied a diagonal GMM on transformed observations. At every time step, the next observation, $\({y_{t + 1}}\)$, has been passed through a flow$-$based neural network to obtain a much simpler distribution. Experimental results for a reinforcement learning problem verify the superiority of the proposed method to the base$-$line method in terms of Negative Log$-$Likelihood (NLL) for RMDN and the cumulative reward for a controller with fewer population size.