 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-based classification of interviews for mental health -- juxtaposing the state of the art
Paper and Code


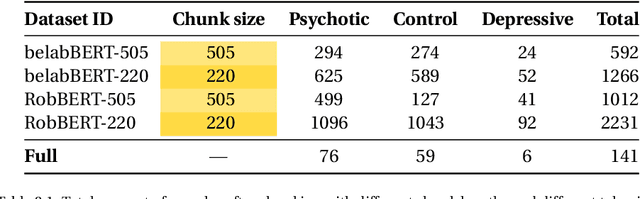
Currently, the state of the art for classification of psychiatric illness is based on audio-based classification. This thesis aims to design and evaluate a state of the art text classification network on this challenge. The hypothesis is that a well designed text-based approach poses a strong competition against the state-of-the-art audio based approaches. Dutch natural language models are being limited by the scarcity of pre-trained monolingual NLP models, as a result Dutch natural language models have a low capture of long range semantic dependencies over sentences. For this issue, this thesis presents belabBERT, a new Dutch language model extending the RoBERTa[15] architecture. belabBERT is trained on a large Dutch corpus (+32GB) of web crawled texts. After this thesis evaluates the strength of text-based classification, a brief exploration is done, extending the framework to a hybrid text- and audio-based classification. The goal of this hybrid framework is to show the principle of hybridisation with a very basic audio-classification network. The overall goal is to create the foundations for a hybrid psychiatric illness classification, by proving that the new text-based classification is already a strong stand-alone solution.