 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Learning of Point Clouds via Orientation Estimation
Paper and Code
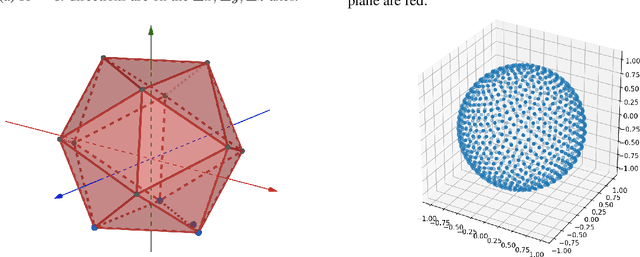

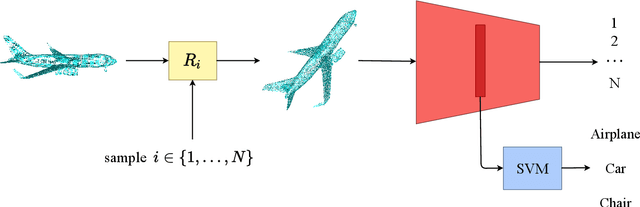
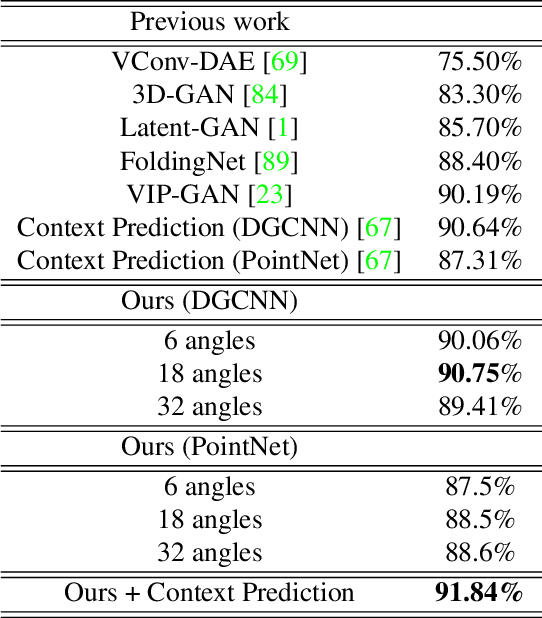
Point clouds provide a compact and efficient representation of 3D shapes. While deep neural networks have achieved impressive results on point cloud learning tasks, they require massive amounts of manually labeled data, which can be costly and time-consuming to collect. In this paper, we leverage 3D self-supervision for learning downstream tasks on point clouds with fewer labels. A point cloud can be rotated in infinitely many ways, which provides a rich label-free source for self-supervision. We consider the auxiliary task of predicting rotations that in turn leads to useful features for other tasks such as shape classification and 3D keypoint prediction. Using experiments on ShapeNet and ModelNet, we demonstrate that our approach outperforms the state-of-the-art. Moreover, features learned by our model are complementary to other self-supervised methods and combining them leads to further performance improvement.