 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIUST at SemEval-2020 Task 9: Sentiment Analysis for Code-Mixed Social Media Text using Deep Neural Networks and Linear Baselines
Paper and Code
Jul 24, 2020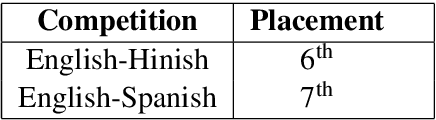
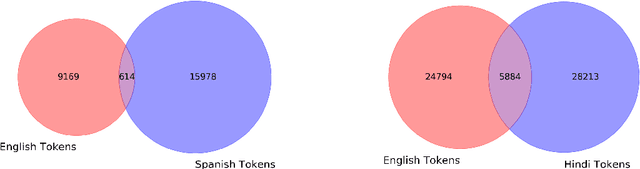

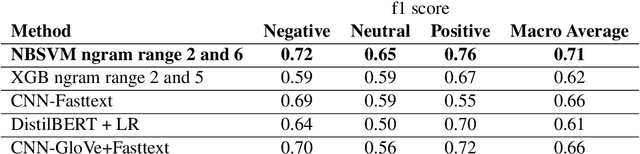
Sentiment Analysis is a well-studied field of Natural Language Processing. However, the rapid growth of social media and noisy content within them poses significant challenges in addressing this problem with well-established methods and tools. One of these challenges is code-mixing, which means using different languages to convey thoughts in social media texts. Our group, with the name of IUST(username: TAHA), participated at the SemEval-2020 shared task 9 on Sentiment Analysis for Code-Mixed Social Media Text, and we have attempted to develop a system to predict the sentiment of a given code-mixed tweet. We used different preprocessing techniques and proposed to use different methods that vary from NBSVM to more complicated deep neural network models. Our best performing method obtains an F1 score of 0.751 for the Spanish-English sub-task and 0.706 over the Hindi-English sub-task.