 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-Efficient Speech Mask Estimation for Multi-Channel Speech Enhancement
Paper and Code
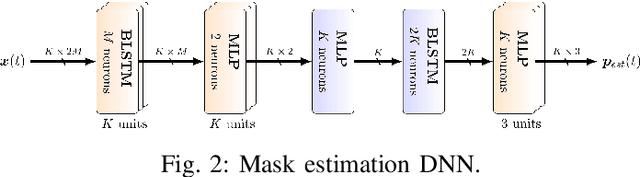
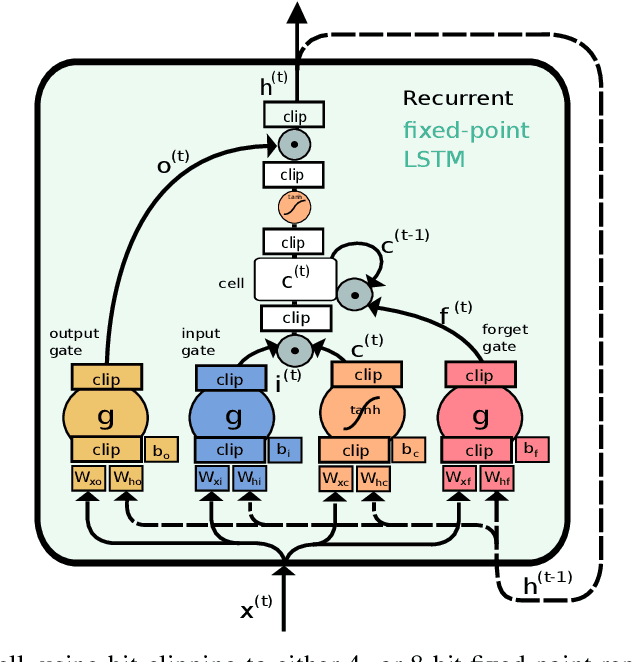
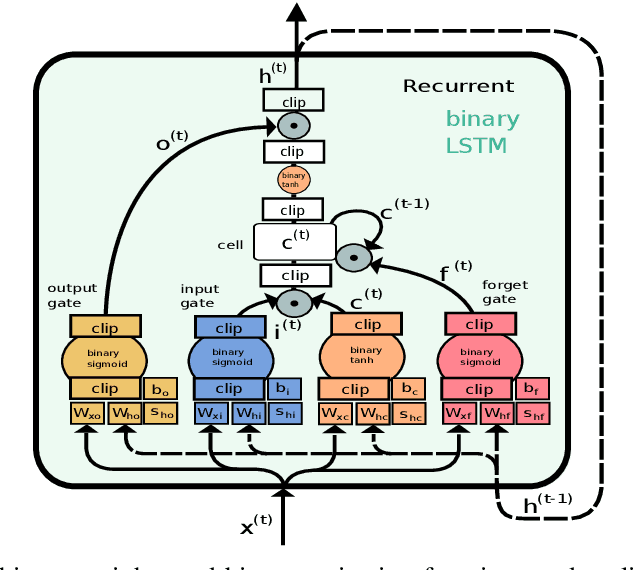
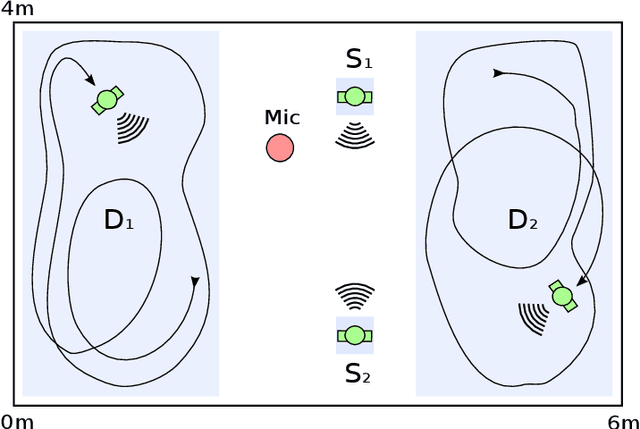
While machine learning techniques are traditionally resource intensive, we are currently witnessing an increased interest in hardware and energy efficient approaches. This need for resource-efficient machine learning is primarily driven by the demand for embedded systems and their usage in ubiquitous computing and IoT applications. In this article, we provide a resource-efficient approach for multi-channel speech enhancement based on Deep Neural Networks (DNNs). In particular, we use reduced-precision DNNs for estimating a speech mask from noisy, multi-channel microphone observations. This speech mask is used to obtain either the Minimum Variance Distortionless Response (MVDR) or Generalized Eigenvalue (GEV) beamformer. In the extreme case of binary weights and reduced precision activations, a significant reduction of execution time and memory footprint is possible while still obtaining an audio quality almost on par to single-precision DNNs and a slightly larger Word Error Rate (WER) for single speaker scenarios using the WSJ0 speech corpus.