 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Data to Speed-up Sorted Table Search Procedures: Methodology and Practical Guidelines
Paper and Code
Jul 30, 2020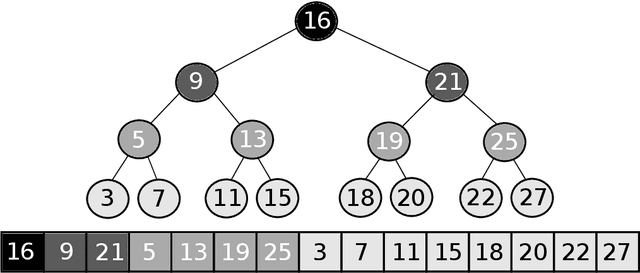
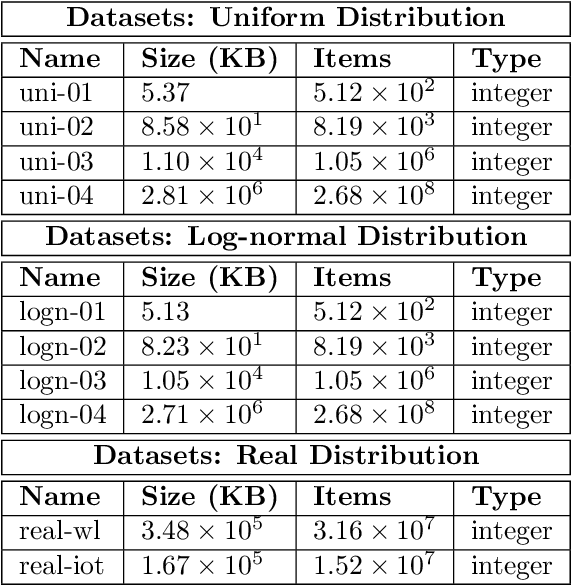
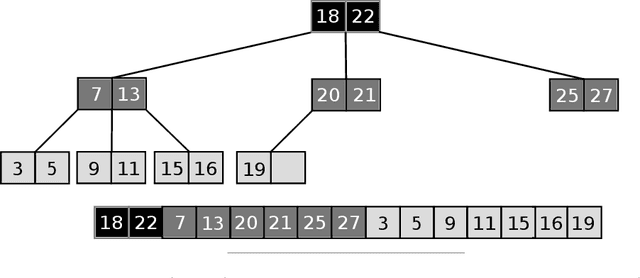
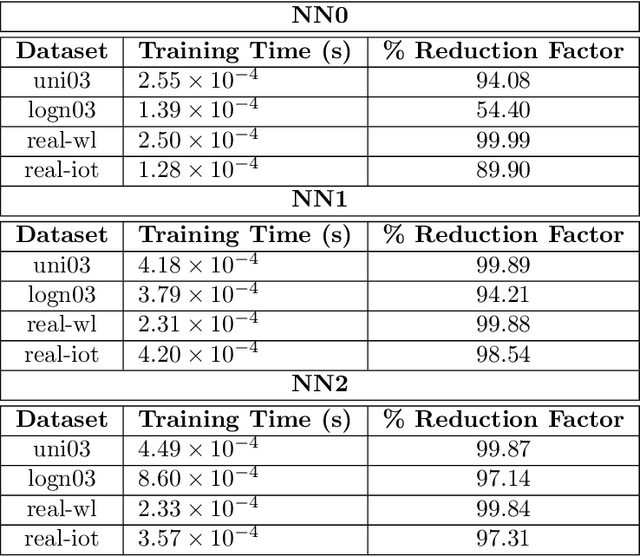
Sorted Table Search Procedures are the quintessential query-answering tool, with widespread usage that now includes also Web Applications, e.g, Search Engines (Google Chrome) and ad Bidding Systems (AppNexus). Speeding them up, at very little cost in space, is still a quite significant achievement. Here we study to what extend Machine Learning Techniques can contribute to obtain such a speed-up via a systematic experimental comparison of known efficient implementations of Sorted Table Search procedures, with different Data Layouts, and their Learned counterparts developed here. We characterize the scenarios in which those latter can be profitably used with respect to the former, accounting for both CPU and GPU computing. Our approach contributes also to the study of Learned Data Structures, a recent proposal to improve the time/space performance of fundamental Data Structures, e.g., B-trees, Hash Tables, Bloom Filters. Indeed, we also formalize an Algorithmic Paradigm of Learned Dichotomic Sorted Table Search procedures that naturally complements the Learned one proposed here and that characterizes most of the known Sorted Table Search Procedures as having a "learning phase" that approximates Simple Linear Regression.