 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomy of Catastrophic Forgetting: Hidden Representations and Task Semantics
Paper and Code
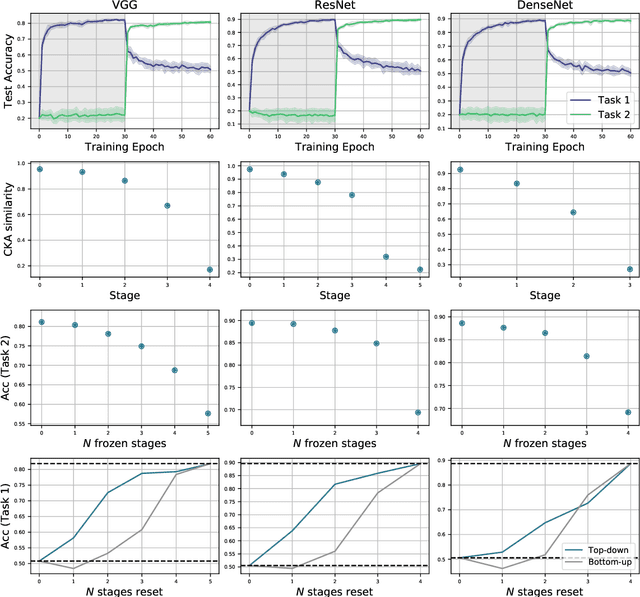
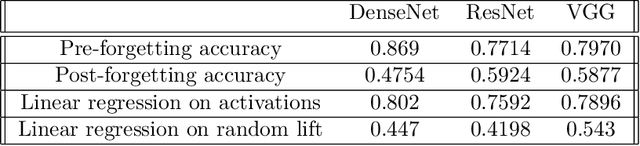


A central challenge in developing versatile machine learning systems is catastrophic forgetting: a model trained on tasks in sequence will suffer significant performance drops on earlier tasks. Despite the ubiquity of catastrophic forgetting, there is limited understanding of the underlying process and its causes. In this paper, we address this important knowledge gap, investigating how forgetting affects representations in neural network models. Through representational analysis techniques, we find that deeper layers are disproportionately the source of forgetting. Supporting this, a study of methods to mitigate forgetting illustrates that they act to stabilize deeper layers. These insights enable the development of an analytic argument and empirical picture relating the degree of forgetting to representational similarity between tasks. Consistent with this picture, we observe maximal forgetting occurs for task sequences with intermediate similarity. We perform empirical studies on the standard split CIFAR-10 setup and also introduce a novel CIFAR-100 based task approximating realistic input distribution shift.