 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Wavelet SSIM based Image Data Augmentation
Paper and Code
Jul 11, 2020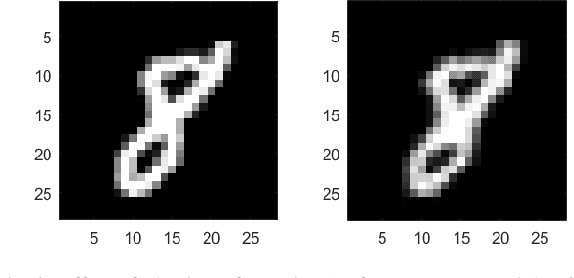
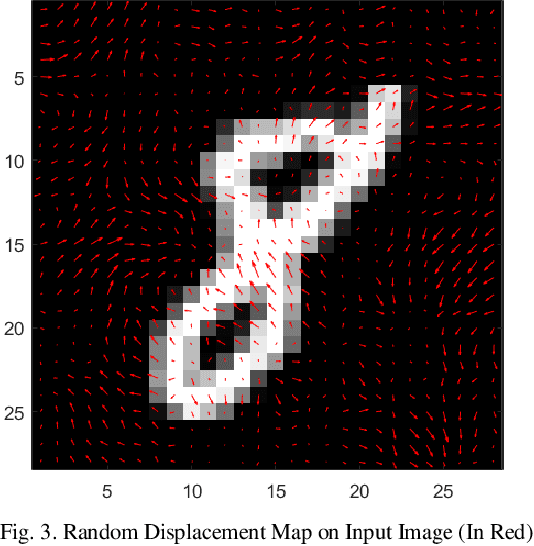

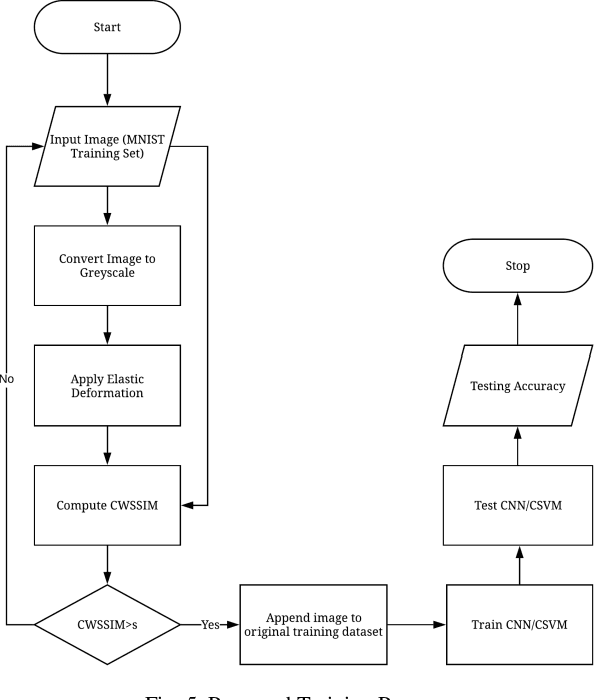
One of the biggest problems in neural learning networks is the lack of training data available to train the network. Data augmentation techniques over the past few years, have therefore been developed, aiming to increase the amount of artificial training data with the limited number of real world samples. In this paper, we look particularly at the MNIST handwritten dataset an image dataset used for digit recognition, and the methods of data augmentation done on this data set. We then take a detailed look into one of the most popular augmentation techniques used for this data set elastic deformation; and highlight its demerit of degradation in the quality of data, which introduces irrelevant data to the training set. To decrease this irrelevancy, we propose to use a similarity measure called Complex Wavelet Structural Similarity Index Measure (CWSSIM) to selectively filter out the irrelevant data before we augment the data set. We compare our observations with the existing augmentation technique and find our proposed method works yields better results than the existing technique.