 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Joint Sparse Non-negative Matrix Factorization Framework for Identifying the Common and Subject-specific Functional Units of Tongue Motion During Speech
Paper and Code
Jul 09, 2020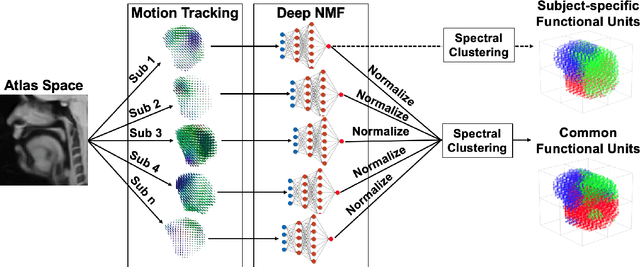

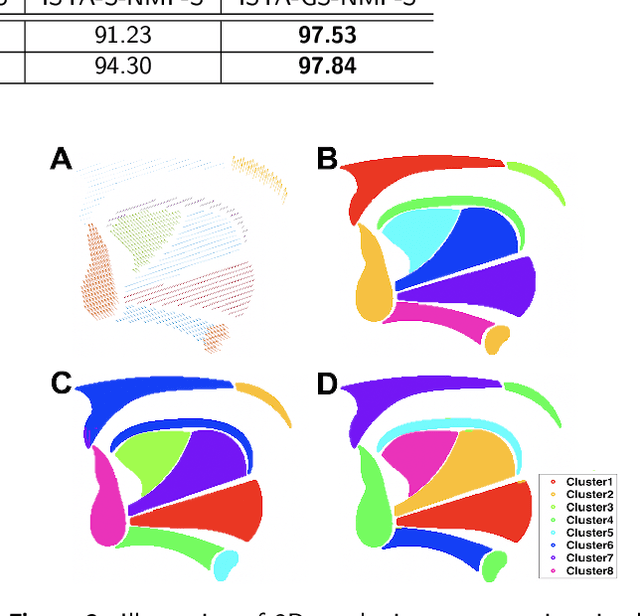
Intelligible speech is produced by creating varying internal local muscle groupings---i.e., functional units---that are generated in a systematic and coordinated manner. There are two major challenges in characterizing and analyzing functional units. First, due to the complex and convoluted nature of tongue structure and function, it is of great importance to develop a method that can accurately decode complex muscle coordination patterns during speech. Second, it is challenging to keep identified functional units across subjects comparable due to their substantial variability. In this work, to address these challenges, we develop a new deep learning framework to identify common and subject-specific functional units of tongue motion during speech. Our framework hinges on joint deep graph-regularized sparse non-negative matrix factorization (NMF) using motion quantities derived from displacements by tagged Magnetic Resonance Imaging. More specifically, we transform NMF with sparse and manifold regularizations into modular architectures akin to deep neural networks by means of unfolding the Iterative Shrinkage-Thresholding Algorithm to learn interpretable building blocks and associated weighting map. We then apply spectral clustering to common and subject-specific functional units. Experiments carried out with simulated datasets show that the proposed method surpasses the comparison methods. Experiments carried out with in vivo tongue motion datasets show that the proposed method can determine the common and subject-specific functional units with increased interpretability and decreased size variability.