 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransparency Tools for Fairness in AI (Luskin)
Paper and Code
Jul 09, 2020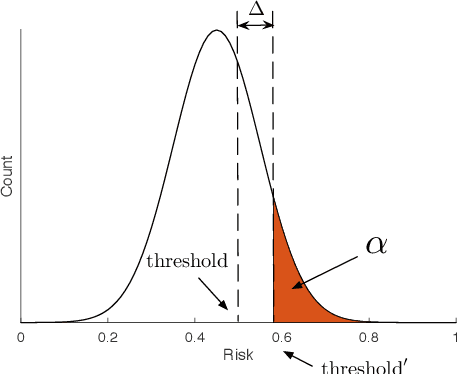
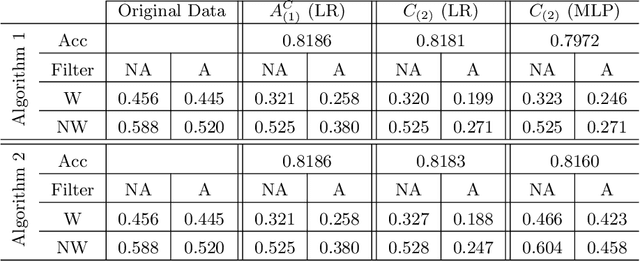
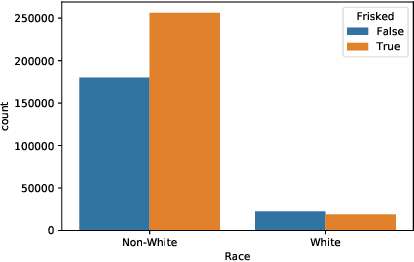
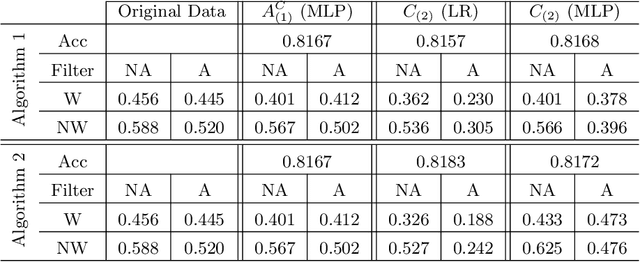
We propose new tools for policy-makers to use when assessing and correcting fairness and bias in AI algorithms. The three tools are: - A new definition of fairness called "controlled fairness" with respect to choices of protected features and filters. The definition provides a simple test of fairness of an algorithm with respect to a dataset. This notion of fairness is suitable in cases where fairness is prioritized over accuracy, such as in cases where there is no "ground truth" data, only data labeled with past decisions (which may have been biased). - Algorithms for retraining a given classifier to achieve "controlled fairness" with respect to a choice of features and filters. Two algorithms are presented, implemented and tested. These algorithms require training two different models in two stages. We experiment with combinations of various types of models for the first and second stage and report on which combinations perform best in terms of fairness and accuracy. - Algorithms for adjusting model parameters to achieve a notion of fairness called "classification parity". This notion of fairness is suitable in cases where accuracy is prioritized. Two algorithms are presented, one which assumes that protected features are accessible to the model during testing, and one which assumes protected features are not accessible during testing. We evaluate our tools on three different publicly available datasets. We find that the tools are useful for understanding various dimensions of bias, and that in practice the algorithms are effective in starkly reducing a given observed bias when tested on new data.