Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Transformers Need Deep Long-Range Memory
Paper and Code
Jul 07, 2020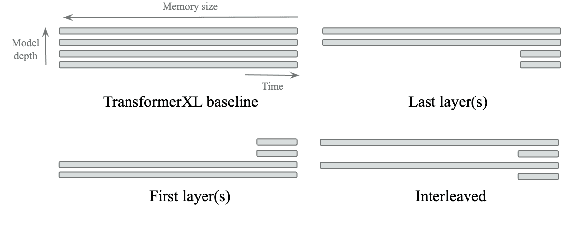
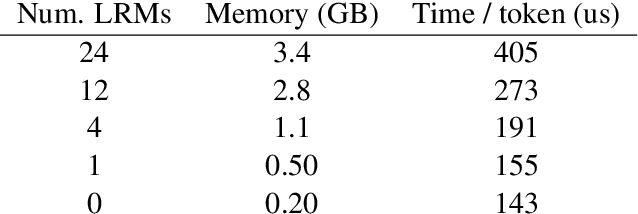
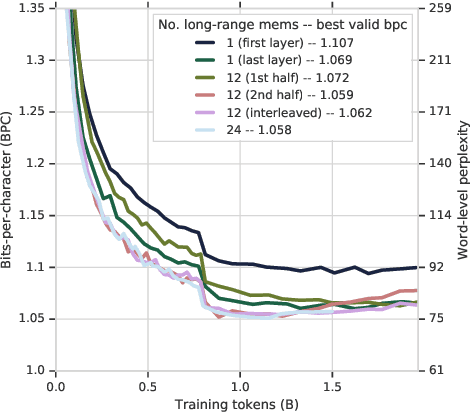
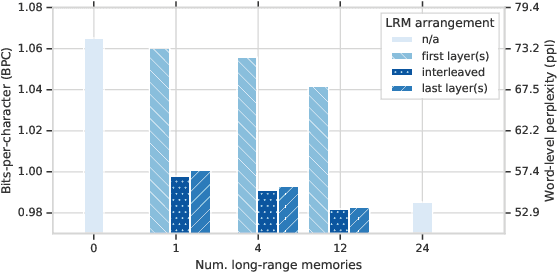
Deep attention models have advanced the modelling of sequential data across many domains. For language modelling in particular, the Transformer-XL -- a Transformer augmented with a long-range memory of past activations -- has been shown to be state-of-the-art across a variety of well-studied benchmarks. The Transformer-XL incorporates a long-range memory at every layer of the network, which renders its state to be thousands of times larger than RNN predecessors. However it is unclear whether this is necessary. We perform a set of interventions to show that comparable performance can be obtained with 6X fewer long range memories and better performance can be obtained by limiting the range of attention in lower layers of the network.
* published at 58th Annual Meeting of the Association for Computational
Linguistics. 6 pages, 4 figures, 1 table
View paper on