 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretrained Semantic Speech Embeddings for End-to-End Spoken Language Understanding via Cross-Modal Teacher-Student Learning
Paper and Code
Jul 03, 2020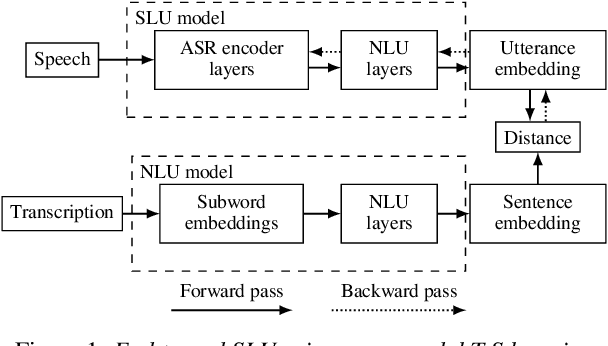
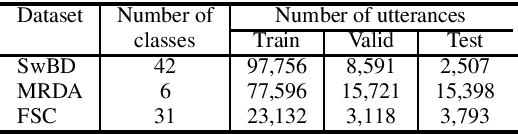

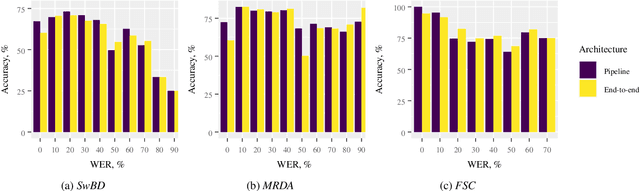
Spoken language understanding is typically based on pipeline architectures including speech recognition and natural language understanding steps. Therefore, these components are optimized independently from each other and the overall system suffers from error propagation. In this paper, we propose a novel training method that enables pretrained contextual embeddings such as BERT to process acoustic features. In particular, we extend it with an encoder of pretrained speech recognition systems in order to construct end-to-end spoken language understanding systems. Our proposed method is based on the teacher-student framework across speech and text modalities that aligns the acoustic and the semantic latent spaces. Experimental results in three benchmark datasets show that our system reaches the pipeline architecture performance without using any training data and outperforms it after fine-tuning with only a few examples.