 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Pipeline for Patient Diagnosis Prediction Using Electronic Health Records
Paper and Code
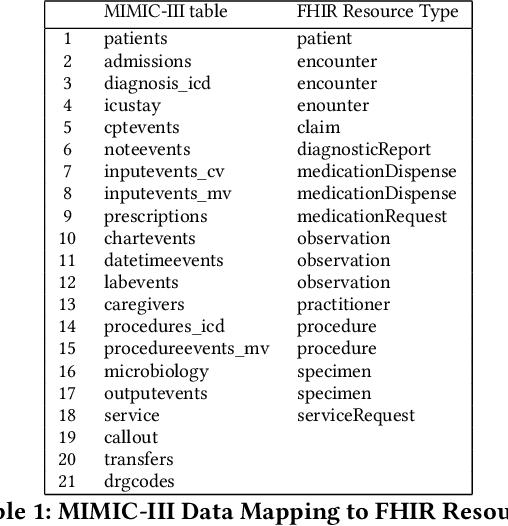
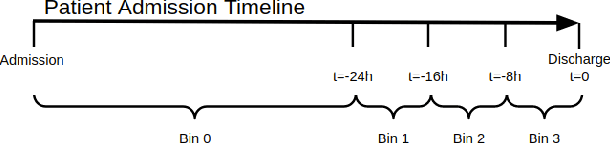
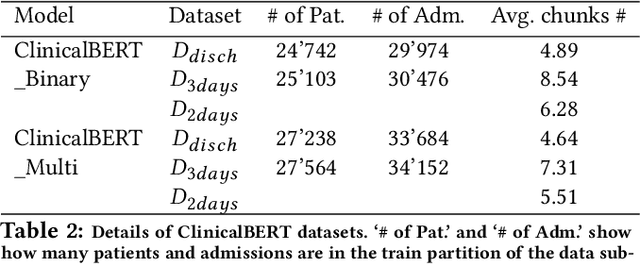

Augmentation of disease diagnosis and decision-making in healthcare with machine learning algorithms is gaining much impetus in recent years. In particular, in the current epidemiological situation caused by COVID-19 pandemic, swift and accurate prediction of disease diagnosis with machine learning algorithms could facilitate identification and care of vulnerable clusters of population, such as those having multi-morbidity conditions. In order to build a useful disease diagnosis prediction system, advancement in both data representation and development of machine learning architectures are imperative. First, with respect to data collection and representation, we face severe problems due to multitude of formats and lack of coherency prevalent in Electronic Health Records (EHRs). This causes hindrance in extraction of valuable information contained in EHRs. Currently, no universal global data standard has been established. As a useful solution, we develop and publish a Python package to transform public health dataset into an easy to access universal format. This data transformation to an international health data format facilitates researchers to easily combine EHR datasets with clinical datasets of diverse formats. Second, machine learning algorithms that predict multiple disease diagnosis categories simultaneously remain underdeveloped. We propose two novel model architectures in this regard. First, DeepObserver, which uses structured numerical data to predict the diagnosis categories and second, ClinicalBERT_Multi, that incorporates rich information available in clinical notes via natural language processing methods and also provides interpretable visualizations to medical practitioners. We show that both models can predict multiple diagnoses simultaneously with high accuracy.