 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Will Generative Adversarial Imitation Learning Algorithms Attain Global Convergence
Paper and Code
Jun 25, 2020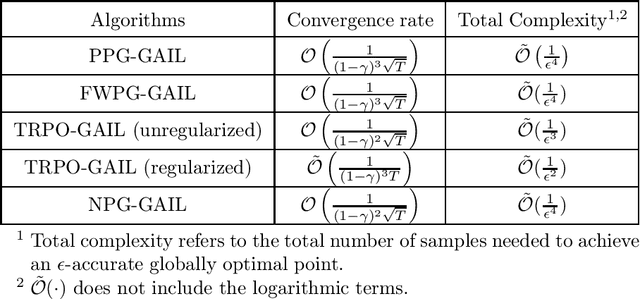
Generative adversarial imitation learning (GAIL) is a popular inverse reinforcement learning approach for jointly optimizing policy and reward from expert trajectories. A primary question about GAIL is whether applying a certain policy gradient algorithm to GAIL attains a global minimizer (i.e., yields the expert policy), for which existing understanding is very limited. Such global convergence has been shown only for the linear (or linear-type) MDP and linear (or linearizable) reward. In this paper, we study GAIL under general MDP and for nonlinear reward function classes (as long as the objective function is strongly concave with respect to the reward parameter). We characterize the global convergence with a sublinear rate for a broad range of commonly used policy gradient algorithms, all of which are implemented in an alternating manner with stochastic gradient ascent for reward update, including projected policy gradient (PPG)-GAIL, Frank-Wolfe policy gradient (FWPG)-GAIL, trust region policy optimization (TRPO)-GAIL and natural policy gradient (NPG)-GAIL. This is the first systematic theoretical study of GAIL for global convergence.