 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat shapes feature representations? Exploring datasets, architectures, and training
Paper and Code

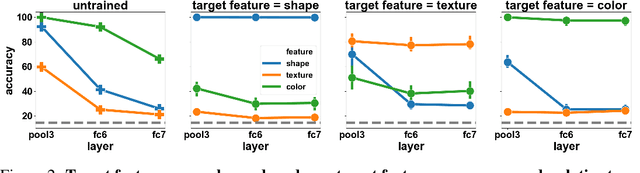
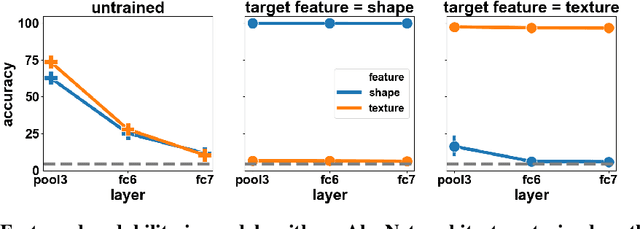
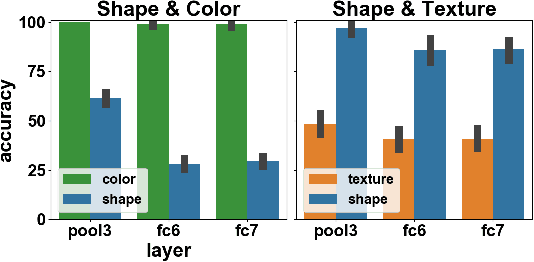
In naturalistic learning problems, a model's input contains a wide range of features, some useful for the task at hand, and others not. Of the useful features, which ones does the model use? Of the task-irrelevant features, which ones does the model represent? Answers to these questions are important for understanding the basis of models' decisions, for example to ensure they are equitable and unbiased, as well as for building new models that learn versatile, adaptable representations useful beyond their original training task. We study these questions using synthetic datasets in which the task-relevance of different input features can be controlled directly. We find that when two features redundantly predict the label, the model preferentially represents one, and its preference reflects what was most linearly decodable from the untrained model. Over training, task-relevant features are enhanced, and task-irrelevant features are partially suppressed. Interestingly, in some cases, an easier, weakly predictive feature can suppress a more strongly predictive, but harder one. Additionally, models trained to recognize both easy and hard features learn representations most similar to models that use only the easy feature. Further, easy features lead to more consistent representations across model runs than do hard features. Finally, models have more in common with an untrained model than with models trained on a different task. Our results highlight the complex processes that determine which features a model represents.