 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neural Network for Determination of Latent Dimensionality in Nonnegative Matrix Factorization
Paper and Code
Jun 22, 2020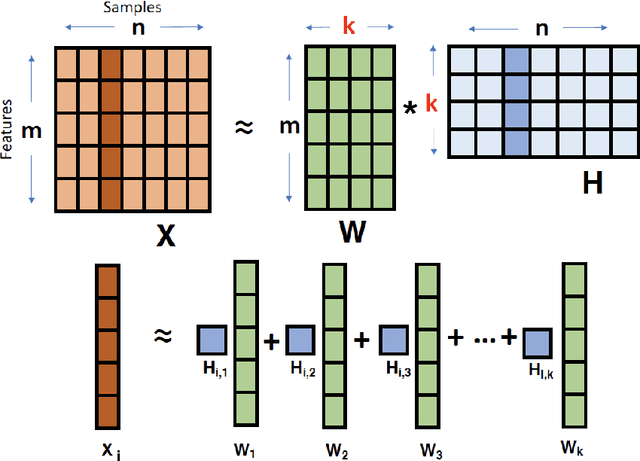
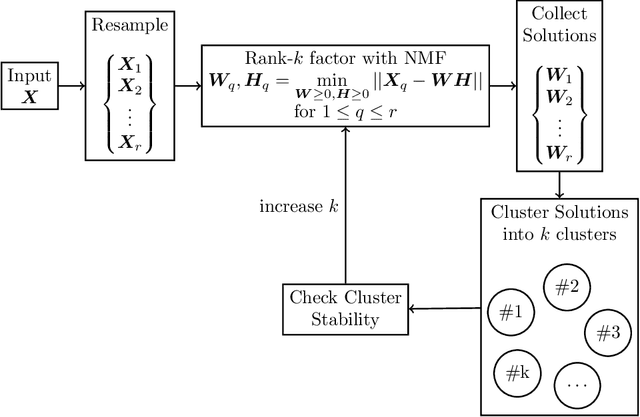
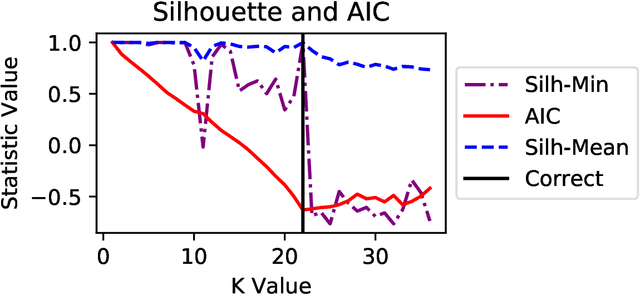
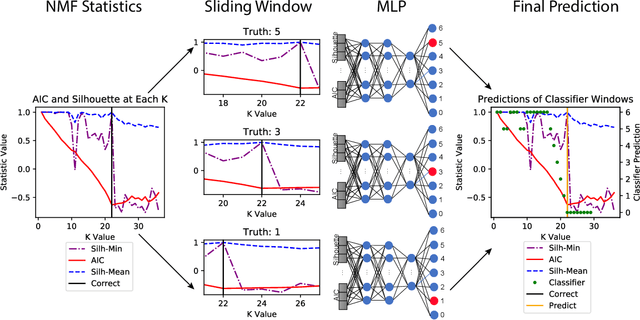
Non-negative Matrix Factorization (NMF) has proven to be a powerful unsupervised learning method for uncovering hidden features in complex and noisy data sets with applications in data mining, text recognition, dimension reduction, face recognition, anomaly detection, blind source separation, and many other fields. An important input for NMF is the latent dimensionality of the data, that is, the number of hidden features, K, present in the explored data set. Unfortunately, this quantity is rarely known a priori. We utilize a supervised machine learning approach in combination with a recent method for model determination, called NMFk, to determine the number of hidden features automatically. NMFk performs a set of NMF simulations on an ensemble of matrices, obtained by bootstrapping the initial data set, and determines which K produces stable groups of latent features that reconstruct the initial data set well. We then train a Multi-Layer Perceptron (MLP) classifier network to determine the correct number of latent features utilizing the statistics and characteristics of the NMF solutions, obtained from NMFk. In order to train the MLP classifier, a training set of 58,660 matrices with predetermined latent features were factorized with NMFk. The MLP classifier in conjunction with NMFk maintains a greater than 95% success rate when applied to a held out test set. Additionally, when applied to two well-known benchmark data sets, the swimmer and MIT face data, NMFk/MLP correctly recovered the established number of hidden features. Finally, we compared the accuracy of our method to the ARD, AIC and Stability-based methods.