 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Self-Critical Training for Transformer in Visual Paragraph Generation
Paper and Code
Jun 21, 2020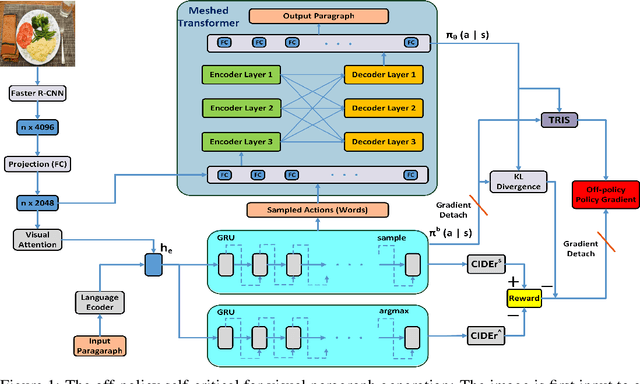
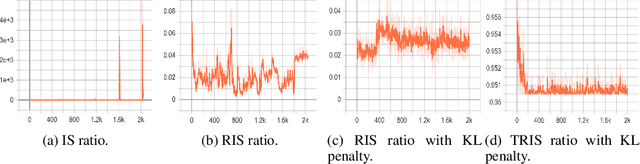


Recently, several approaches have been proposed to solve language generation problems. Transformer is currently state-of-the-art seq-to-seq model in language generation. Reinforcement Learning (RL) is useful in solving exposure bias and the optimisation on non-differentiable metrics in seq-to-seq language learning. However, Transformer is hard to combine with RL as the costly computing resource is required for sampling. We tackle this problem by proposing an off-policy RL learning algorithm where a behaviour policy represented by GRUs performs the sampling. We reduce the high variance of importance sampling (IS) by applying the truncated relative importance sampling (TRIS) technique and Kullback-Leibler (KL)-control concept. TRIS is a simple yet effective technique, and there is a theoretical proof that KL-control helps to reduce the variance of IS. We formulate this off-policy RL based on self-critical sequence training. Specifically, we use a Transformer-based captioning model as the target policy and use an image-guided language auto-encoder as the behaviour policy to explore the environment. The proposed algorithm achieves state-of-the-art performance on the visual paragraph generation and improved results on image captioning.