 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalization Matters in Zero-Shot Learning
Paper and Code
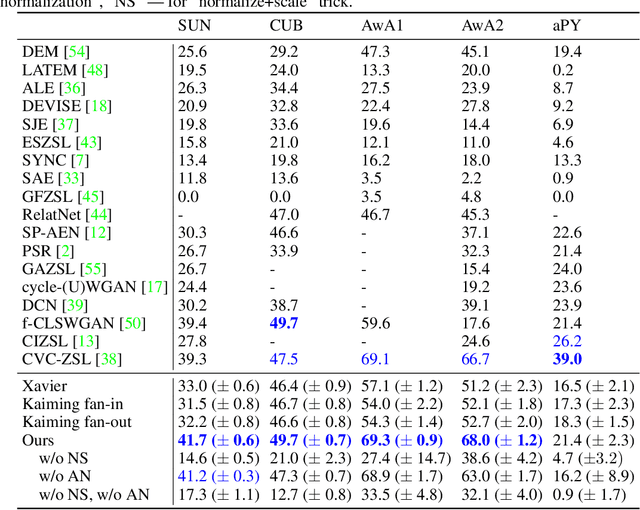
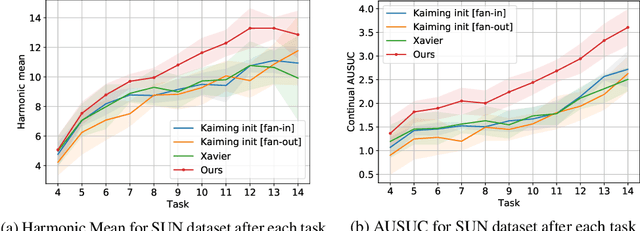
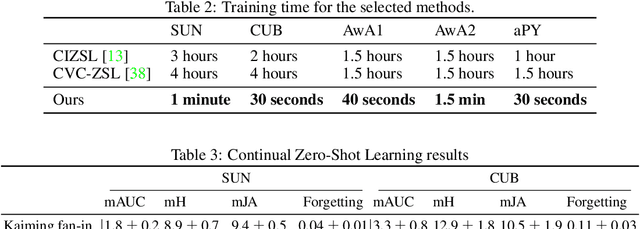
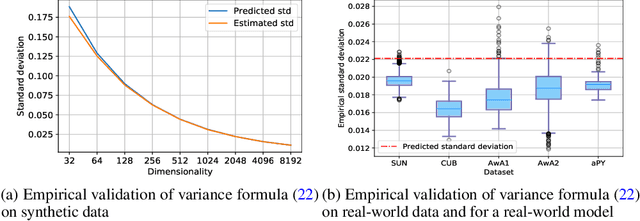
An ability to grasp new concepts from their descriptions is one of the key features of human intelligence, and zero-shot learning (ZSL) aims to incorporate this property into machine learning models. In this paper, we theoretically investigate two very popular tricks used in ZSL: "normalize+scale" trick and attributes normalization and show how they help to preserve a signal's variance in a typical model during a forward pass. Next, we demonstrate that these two tricks are not enough to normalize a deep ZSL network. We derive a new initialization scheme, which allows us to demonstrate strong state-of-the-art results on 4 out of 5 commonly used ZSL datasets: SUN, CUB, AwA1, and AwA2 while being on average 2 orders faster than the closest runner-up. Finally, we generalize ZSL to a broader problem -- Continual Zero-Shot Learning (CZSL) and test our ideas in this new setup. The source code to reproduce all the results is available at https://github.com/universome/czsl.