 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Discrete to Continuous Convolution Layers
Paper and Code
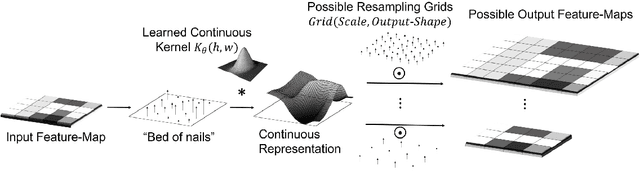
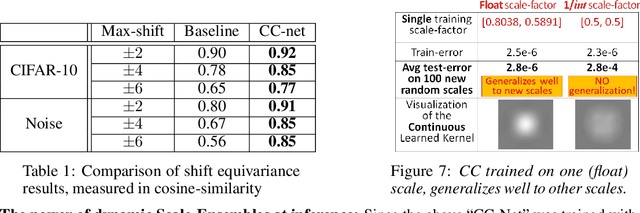
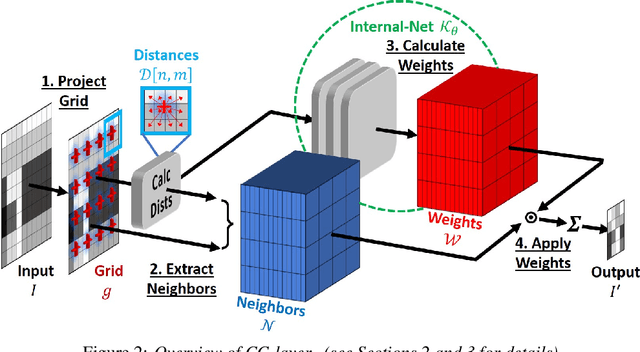

A basic operation in Convolutional Neural Networks (CNNs) is spatial resizing of feature maps. This is done either by strided convolution (donwscaling) or transposed convolution (upscaling). Such operations are limited to a fixed filter moving at predetermined integer steps (strides). Spatial sizes of consecutive layers are related by integer scale factors, predetermined at architectural design, and remain fixed throughout training and inference time. We propose a generalization of the common Conv-layer, from a discrete layer to a Continuous Convolution (CC) Layer. CC Layers naturally extend Conv-layers by representing the filter as a learned continuous function over sub-pixel coordinates. This allows learnable and principled resizing of feature maps, to any size, dynamically and consistently across scales. Once trained, the CC layer can be used to output any scale/size chosen at inference time. The scale can be non-integer and differ between the axes. CC gives rise to new freedoms for architectural design, such as dynamic layer shapes at inference time, or gradual architectures where the size changes by a small factor at each layer. This gives rise to many desired CNN properties, new architectural design capabilities, and useful applications. We further show that current Conv-layers suffer from inherent misalignments, which are ameliorated by CC layers.