 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecord fusion: A learning approach
Paper and Code
Jun 18, 2020
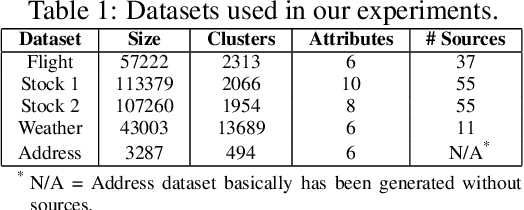
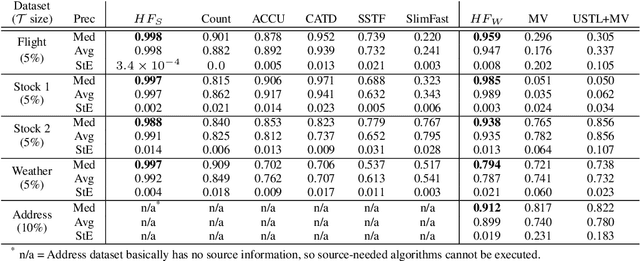
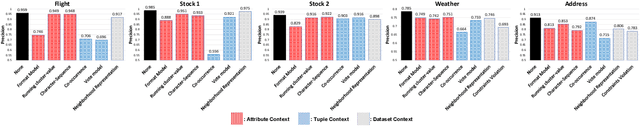
Record fusion is the task of aggregating multiple records that correspond to the same real-world entity in a database. We can view record fusion as a machine learning problem where the goal is to predict the "correct" value for each attribute for each entity. Given a database, we use a combination of attribute-level, recordlevel, and database-level signals to construct a feature vector for each cell (or (row, col)) of that database. We use this feature vector alongwith the ground-truth information to learn a classifier for each of the attributes of the database. Our learning algorithm uses a novel stagewise additive model. At each stage, we construct a new feature vector by combining a part of the original feature vector with features computed by the predictions from the previous stage. We then learn a softmax classifier over the new feature space. This greedy stagewise approach can be viewed as a deep model where at each stage, we are adding more complicated non-linear transformations of the original feature vector. We show that our approach fuses records with an average precision of ~98% when source information of records is available, and ~94% without source information across a diverse array of real-world datasets. We compare our approach to a comprehensive collection of data fusion and entity consolidation methods considered in the literature. We show that our approach can achieve an average precision improvement of ~20%/~45% with/without source information respectively.