 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVietnamese Word Segmentation with SVM: Ambiguity Reduction and Suffix Capture
Paper and Code


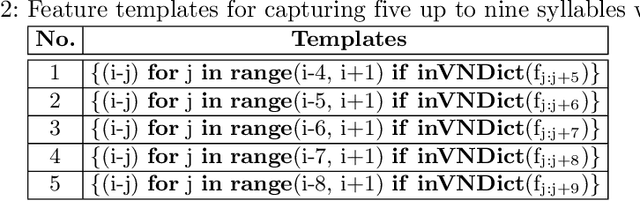
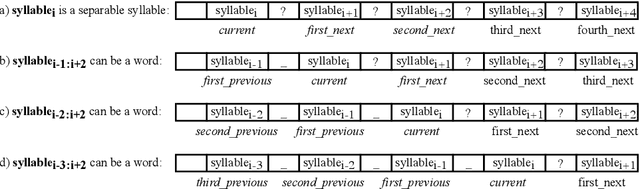
In this paper, we approach Vietnamese word segmentation as a binary classification by using the Support Vector Machine classifier. We inherit features from prior works such as n-gram of syllables, n-gram of syllable types, and checking conjunction of adjacent syllables in the dictionary. We propose two novel ways to feature extraction, one to reduce the overlap ambiguity and the other to increase the ability to predict unknown words containing suffixes. Different from UETsegmenter and RDRsegmenter, two state-of-the-art Vietnamese word segmentation methods, we do not employ the longest matching algorithm as an initial processing step or any post-processing technique. According to experimental results on benchmark Vietnamese datasets, our proposed method obtained a better F1-score than the prior state-of-the-art methods UETsegmenter, and RDRsegmenter.