 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvenance for Linguistic Corpora Through Nanopublications
Paper and Code
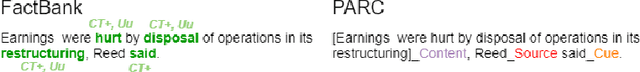
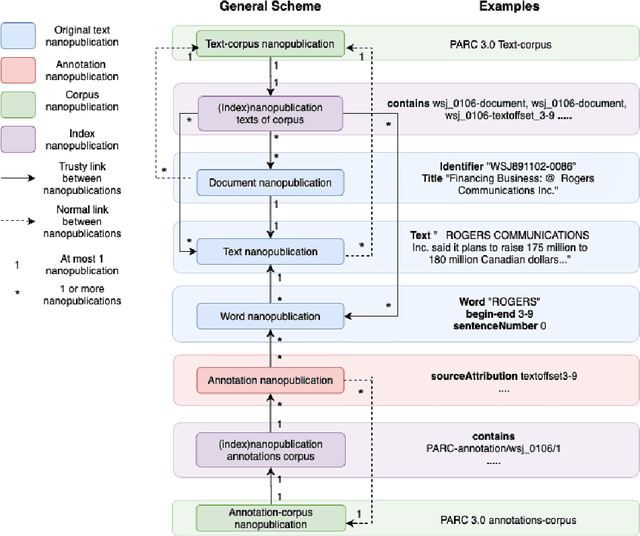
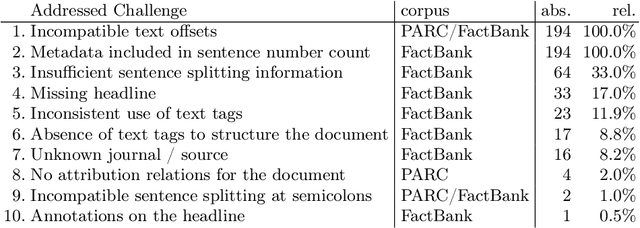
Research in Computational Linguistics is dependent on text corpora for training and testing new tools and methodologies. While there exists a plethora of annotated linguistic information, these corpora are often not interoperable without significant manual work. Moreover, these annotations might have adapted and might have evolved into different versions, making it challenging for researchers to know the data's provenance and merge it with other annotated corpora. In other words, these variations affect the interoperability between existing corpora. This paper addresses this issue with a case study on event annotated corpora and by creating a new, more interoperable representation of this data in the form of nanopublications. We demonstrate how linguistic annotations from separate corpora can be merged through a similar format to thereby make annotation content simultaneously accessible. The process for developing the nanopublications is described, and SPARQL queries are performed to extract interesting content from the new representations. The queries show that information of multiple corpora can now be retrieved more easily and effectively with the automated interoperability of the information of different corpora in a uniform data format.